AI document classification
Project summary
Our custom two-API architecture – Parser API (OCR and vectorization capabilities) along with Classification API (AI powering multilabel categorization) – is designed to enable the automation of documents in construction. The solution is fit for multipage and image-only PDF documents and achieves enterprise-grade accuracy.
We achieved document-level and label-level accuracy of 96% and 98% across 31 industry-specific classes.
Project overview
Our client is a European provider of project and document management tools used in construction and engineering. The comprehensive cloud-based solution is available both for mobile and desktop platforms. It is mostly used by architects, engineers, real estate developers, housebuilders, and contractors.
The company has more than two decades of experience in providing digital solutions for the construction industry. It strives to keep up with the times and offer their customers the most efficient construction management solutions. They approached Abto Software with the task of implementing an automated document classification service for their construction DMS (Document Management System).
Get accuracy, forget errors
Contact us

AI Document Classification
Abto Software are experts in implementing AI for automating various business processes. Our solutions vary from customer support automation for FinTech to demand forecasting for retail. This time, we had to implement an AI service for automatic document classification within a construction DMS.
Our client wanted to solve the main end-user problem of their customers. That is an annoying and time-consuming process of manual input of the document details into the DMS. Since this task is very tedious, users often skipped it. This caused many malfunctions in other modules of the document management system. We aimed to automate the classification process and ensure a smooth user journey.
The project has followed several phases that reflect our usual approach to delivering AI automation solutions.
Phase 0. Dataset analysis
As a first step, we analyzed the dataset provided by our client. The documents submitted by users of the construction Document Management System included Microsoft Office files (DOC, XLS), scanned and digitally created PDFs, images (PNG, JPEG, BPM), and AutoCAD drawings (DWG).
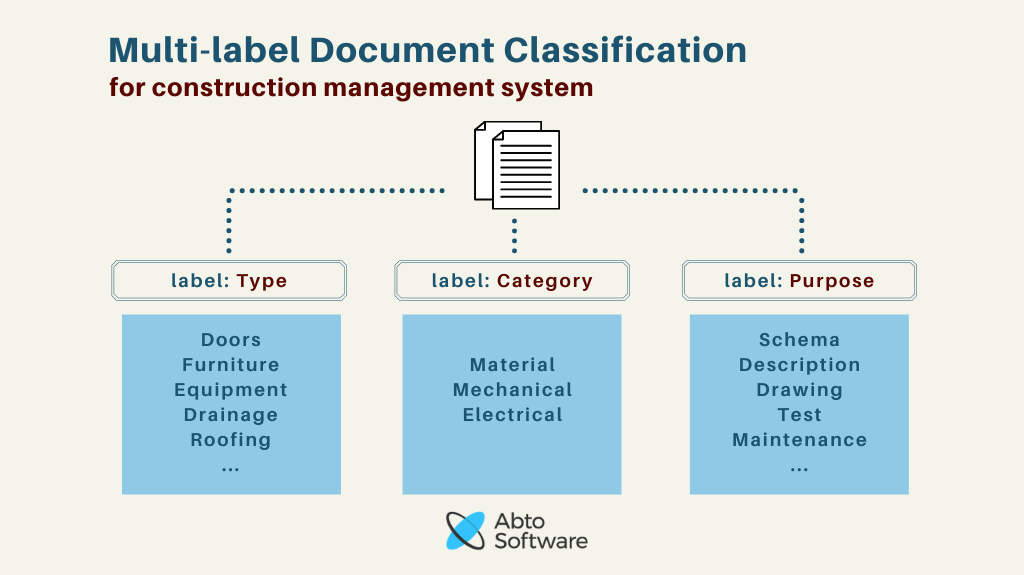
The task was to assign three labels to each of the documents. Each label contains from 3 to 18 classes. The dataset included around 14,000 documents per label, from 200 to 11,000 documents per class.
This type of document classification is called multi-label document classification as each document can be assigned more than one label. In our case, a document can have up to three labels. For example, a DOC file including the information about the materials used for a particular furniture item will have three labels: 'furniture', 'material', and 'description'. Each of these labels has also its unique name within the construction DMS – 'Type', 'Category', and 'Purpose'.
Phase 1. OCR and text vectorization
AI models for document classification work by analyzing the text within documents. So one of the most crucial steps in building a comprehensive document classification service is text extraction.
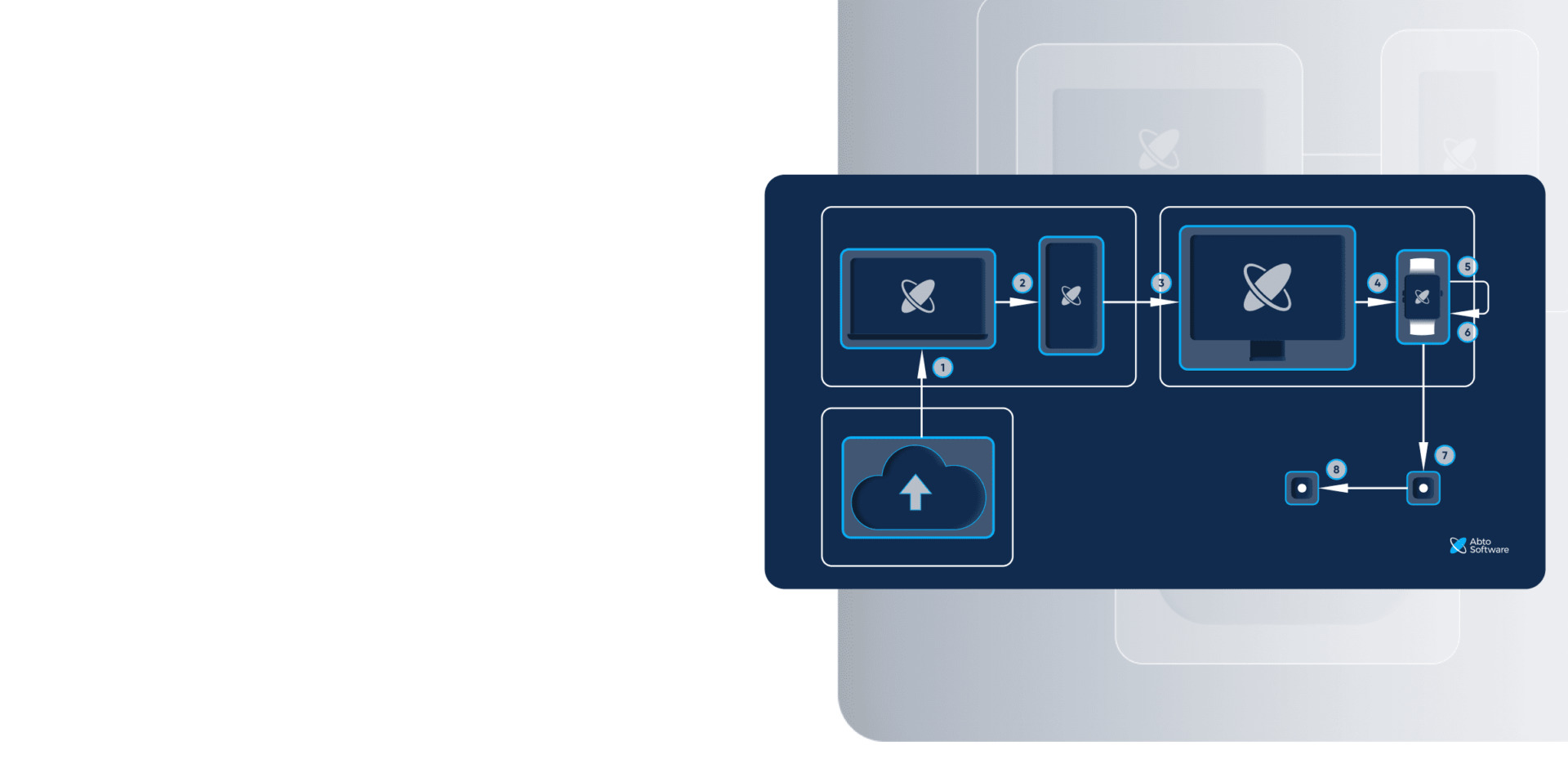
We used Tesseract OCR to build a custom Parser API. First, it performs optical character recognition (OCR) of the non-readable documents. That is scanned documents, images, schemes. Then, it converts extracted text into numerical representation. This NLP technique is called text vectorization.
Phase 2. Investigation of document classification approaches
In the course of selecting the best document classification approach, we have tested more than a dozen Machine Learning models. We focused on achieving the highest accuracy for each of the labels while accounting for an unbalanced dataset.
The rigorous investigation of the document classification approaches allowed us to select an optimal AI model for our customer. We adopted an ensemble learning approach as it proved to have better performance for our type of data. This Machine Learning technique combines individual outputs from several classifiers to reduce errors in predictions. The results from the selected ensemble of classifiers are put to voting to achieve the highest accuracy possible.
It was decided to train three separate ensemble classification models – one per each label. The ML models have the same architecture but are trained on different datasets.
Phase 3. AI model for document classification & its accuracy
We have built an AI-based Document Classification API that receives the results from the Parser API. It delivers the values for three labels along with the accuracies of predictions.
Document classification API output structure
{
"type": "Class", "typeProbability": Accuracy,
"category": "Class", "categoryProbability": Accuracy,
"purpose": "Class", "purposeProbability": Accuracy
}
Document classification API output example
{
"type": "Doors", "typeProbability": 0.99,
"category": "Material", "categoryProbability": 0.97,
"purpose": "Description", "purposeProbability": 0.98
}
We have achieved 98% accuracy for classification within a label and 96% accuracy in classifying documents for all three labels.
Phase 4. Deployment & data security of the document classification service
Our DevOps engineers hosted the document classification solution on Amazon Web Services (AWS). This secure yet flexible cloud hosting platform ensured seamless integration of the document classification service into the client’s document management system.
Since Amazon claims that all AWS services are GDPR compliant, this deployment option allowed us to satisfy stringent client requirements regarding their customers’ data. Our client is also the sole owner of the AWS account and is in full control of their AWS cloud. That means our client can create and manage user policies, monitor data flows, and efficiently respond to any security threats.
Document Classification Solution Structure
The delivered document classification solution comprises two APIs.
- Parser API.Performs document preprocessing, data extraction through OCR, and text vectorization;
- Classification API.Performs AI-enabled multilabel document categorization based on the output of theParser API.
Both APIs are called only by the web-based DMS so they are protected from unsanctioned usage.

Benefits of the Delivered Document Classification Solution
- Smooth user journey. Our solution automates a tedious and often frustrating process of manual entry of the document details into the DMS.
- Extensive document support. The delivered document classification solution supports multipage documents, image-only PDF files and other non-readable documents.
- Robust multilabel classification. The solution performs classification within three different labels, 31 industry-specific classes in total.
- High classification accuracy. We have achieved 96% classification accuracy on the document level and 98% classification accuracy on the label level.
- Enhanced accessibility. As the document classification had to be integrated into the client’s document management system, we deployed it on AWS cloud.
- Reliable scalability. Cloud deployment of the developed APIs allows our client to scale the solution using Amazon scaling services.
- GDPR compliance. The selected development and deployment methods ensure the highest security and customer data protection standards.
Team
- project manager
- solution architect
- 2 data scientists
- Python developer
- DevOps engineer
Project duration
- 2.5 months
Team & Technologies
Tech stack and Data Science tools
- Python
- Scikit-lear
- Tesseract OCR
- Amazon Web Services (AWS)
Investigated text vectorization methods
- Word2vec
- fastText
- GloVe
- TF-IDF
- Universal Sentence Encoder
- BERT
Investigated classification algorithms
- LSTM
- GRU
- RNN
- Bidirectional RNN
- SVM
- KNN
- XGBoost
- AdaBoost
- Logistic Regression
- Decision Trees
- Naïve Bayes methods (Gaussian Naïve Bayes, Multinomial Naive Bayes, Categorical Naïve Bayes)
Conclusions
AI-driven document classification is one of the business processes automation solutions (BPA). It can be integrated into the document management system or used separately. Its main advantage lies in replacing manual work with AI while simultaneously increasing the accuracy of the completed task.
Building an industry-specific document classification solution ensures robust classification and facilitates multi-label classification. Abto Software has years of experience in delivering automation solutions for different industries. We can help you build a document classification service optimized for your particular use case. Discover how implementing Artificial Intelligence and Natural Language Processing can increase your bottom line – contact us by filling out the form below.
Abto Software built an AI document classification service for a construction management system. That is the cloud-based platform used throughout the entire construction lifecycle. It facilitates construction projects from planning and design to operation and maintenance. The document management system (DMS) serves users in the United Kingdom, Ireland, Australia, Qatar, the UAE.
The Abto data science team has combined our experience in OCR, NLP, and AI to connect the construction management software with an automated document classification service. Read how we helped our client streamline document workflow processes for their customers.
Document processing with minimal human intervention
Contact us FAQ
What is a Document Management System?
A DMS, or a Document Management System, is a software solution used to receive, store, update, track, and share digital documents. It automates the document managing workflows within the organization through a variety of tools. They include:
- document classification;
- version control;
- document editing and collaboration;
- robust searching;
- workflow automation;
- file format conversion;
- access control and permissions;
- digital signature, etc.
A substantial number of DMS modules are industry-specific. For example, robust document classification requires a deep understanding of the industry domain.
What is Document Classification?
Document classification or document categorization is the process of assigning predefined labels, or categories, to new documents based on their contents. Depending on the actor that performs classification, document classification can be manual (done by a person) or automated (done by an algorithm).
What technologies are used for Automatic Document Classification?
The state-of-the-art is automatic document classification using Machine Learning. It includes Natural Language Processing (NLP) and Optical Character Recognition (OCR). ML classifiers work with vectorized text that is extracted from documents with NLP and OCR techniques.
What are the stages of Automatic Document Classification?
Automatic document classification usually follows three steps:
- Document preprocessing;
- Data extraction (OCR);
- Document classification using Machine Learning.
What are the benefits of employing AI-based Document Classification?
AI-based document classification has the usual advantages of business process automation (BPA). It is fast, efficient, cost-saving, and more accurate in comparison to manual document classification. Furthermore, building a custom document classifier enables in-depth labeling of the industry-specific documents.