


Demand Forecasting: AI-based Approach and Its Real-World Implementation

AI-based Demand Forecasting Improves Prediction Accuracy
Abto Software has delivered a project to improve the demand forecasting process for industrial goods retailers by using ERP records.
After deeper data analysis and corresponding quality assessment, the focus was shifted to enabling sales forecasting for the top 10 revenue-generating products. The implemented AI-driven model was able to improve prediction accuracy by 5% if compared to a baseline solution.
AI-driven Approach to Demand Forecasting
Abto Software offers fully automated, enterprise-level solutions for precise demand forecasting. We empower the entire decision-making process with an advanced data-driven support system. Our teams also provide our customers with analytics. This way, we enable scenario modeling and evaluate the impact of different internal and external factors on promotions, competitor actions, and more.
On a high level, our approach is comprised of the following stages:
- Initial discovery and analysis
- Model fine-tuning and optimization
Discovery/Exploration
During the first stage, we adapt state-of-the-art open-source frameworks/algorithms to customer’s data. This initial stage of development should also reveal additional factors needed for successful demand prediction project implementation – such as possible data quality and consolidation problems, hidden demand factors, or other insights which can lead to more precise estimation and planning of the next stages.
The data science engineers get familiar with existing data and have a chance to experiment with the selection of ML models and tuning of their parameters to define initial assumptions about the efficiency of different approaches and scenarios where these models may not be as efficient as desired.
This stage results in comparative analysis, which allows us to identify the most promising approaches for demand forecasting in your particular business cases. Data quality is assessed and non-trivial findings are reported to the customer. Also, if needed, additional recommendations are made on how to improve the data collection process in general.
Fine-Tuning/Optimization
During the second stage, we incrementally improve obtained results by adding various pre- and post-processing techniques into forecasting pipeline, fine-tune system parameters, observe the performance and iterate again until required KPIs are reached. After optimized forecasting models are deployed to production, the system is constantly monitored and re-trained as fresh data arrives. This ensures predicted and robust performance over time.
Demand Forecasting Solution Development Process
In order to be even more specific, demand forecasting solution development can be organized in 6 distinct phases presented below. Phases 1 – 4 correspond to the first stage, while phases 4 – 6 correspond to the second stage.
Phase I. Demand Forecasting Process Discovery
The initial step of the demand forecasting solution development process should set up the right direction towards business objectives, so it is essential to come to a clear understanding of the current situation and desired results. On this step key activities are:
- Understanding of business processes and classification of problems (if possible – in measurable units).
- Evaluation of current approaches and definition of desired outcome of project.
- Definition of key model parameters – prediction interval, forecasting horizon, etc.
- Selection and classification of products (grouping/clustering) and partners (distributors/retailers), that will be involved in the project.
- Definition of software/infrastructure environment for the project and desired representation of results.
- Development of preliminary project schedule and budget.
Phase II. Exploitative Data Analysis for Accurate Demand Prediction
The successful implementation of data science approaches is dependent on data quality. Therefore, it is essential to identify and understand inbound data:
- Inventory of existing data: sources, channels, formats, known internal/external factors.
- Identification of data quality problems.
- Selection of datasets for demand prediction model training and verification.
Phase III. Data Engineering
When a sufficient level of data knowledge is reached, it is time to transform data into the form suitable for use in Machine Learning algorithms. The following activities are typical for this stage:
- Data cleaning (decisions on including/excluding specific data entries in modeling).
- Data construction (definition of interpreted/integrated values for better data classification).
- Data transformation (align data from different sources to unified form).
Phase IV. AI/ML-based Demand Forecasting Models Development
In this phase, various modeling techniques are selected and applied for demand forecasting, and their parameters are calibrated to optimal values. Depending on data nature and representation it might be necessary to try several models/techniques to achieve desired results.
In particular, different AI/ML models (or model parameters) may be considered as optimal for different product groups/clusters, especially if product groups are influenced by group-specific factors. The expected outcome of this phase is a set of AI/ML models and their parameters selected for particular partners/products.
In some cases, it might be necessary to go back one or two steps to improve data quality or extend the data set to achieve acceptable results in demand forecasting. The validity of selected models and model parameters is verified using a test dataset.
Phase V. Demand Forecasting Results Evaluation
When AI models and their parameters are approved it is time to evaluate achieved demand forecasting results versus business objectives and existing solutions to ensure that achieved result matches business success criteria. On this phase, the whole process should be reviewed and the next steps are determined:
- Decisions to apply models to a wider range of products/partners.
- Decisions about establishing continuous processes to monitor demand forecasting model behavior in time.
- Hypothesis about additional factors that may influence results and may be included in the next iteration.
Phase VI. Automated Learning and Monitoring
When the decision is made for the continuous use of designed AI/ML models, we need to establish processes of demand forecasting model monitoring to measure the business results, improve prediction accuracy and detect accuracy deviations. The following additional measures are essential when using a developed demand forecasting solution in production:
- Recording of results produced by ML-based demand forecasting models and existing statistical solution and post-factum analysis of forecasts vs. real data.
- Automation of Phase III (data preparation) to prepare for continuous use.
- Establishing of progressive learning by continuous feeding of data to ML models and model parameters tuning. Real world is changing and new demand-influencing factors arise regularly, so it is essential to keep demand forecasting models up-to-date.
Practical Application of AI-powered Approach to Demand Forecasting
The described 5 phases demonstrate the essence of the proposed AI-powered demand forecasting approach. However, for better understanding, it makes sense to support this description with a practical example. Below we present how our demand forecasting approach was applied to predict product sales using ERP data records.
At phase 1, the project objective was identified as an increase in forecasting accuracy of product sales for more accurate budgeting and better inventory management. To measure the efficiency of our forecasting approach, it was agreed to use observational look-up into historical data as a baseline model. This means that the developed AI-based demand forecasting model needs to outperform predictions made as simple look-up in sales records from the preceding period.
Data requirements were set and historical data set was provided by the customer.
After the data became available, the project moved to the next step – phase 2 (data exploration).
Dataset consisted of records that reflect sales operations for 3 years between Jan 2016 and Jan 2019. Market location – the USA, market type – industrial goods. The data was anonymized, as this study contained very sensitive financial information.
In the original database, millions of transactions were registered within a defined period, but just a part of them was provided for analysis. In this case study, we present results for a subset of 1 000 000 rows.
Data was pulled from the SQL database and transformed into pandas.DataFrame. All records have the same data structure, which consists of the following columns:
INTERNAL_ID
ITEM_ID_FIRST_LEVEL
ITEM_ID_SECOND_LEVEL
LOT_TYPE
DATE_AND_TIME
ITEM_QUANTITY
ITEM_UOM
ITEM_UNIT_PRICE
ITEM_ALTERNATIVE_UNIT_PRICE
TRANSACTION_DATE_AND_TIME
SYSTEM_TIME
FISCAL_PERIOD
FISCAL_YEAR
After initial data analysis, it was agreed that only 6 fields (highlighted in bold) out of 13 were useful for further analysis. The data sample used for further research is presented in the table below.
| TRANSACTION_DATE_AND_TIME | ITEM_QUANTITY | ITEM_ID_FIRST_LEVEL | ITEM_ID_SECOND_LEVEL | INTERNAL_ID | ITEM_UNIT_PRICE | |
|---|---|---|---|---|---|---|
| 1. | 2019-02-01 | 2.0 | Prod88 | Sub8 | 90 | 13.5300 |
| 2. | 2019-02-01 | 8.0 | Prod31 | Sub41 | 90 | 2.4000 |
| 3. | 2019-02-01 | 1.5 | Prod31 | 90 | 17.1467 | |
| 4. | 2019-02-01 | 16.0 | Prod39 | Sub12 | 90 | 4.3863 |
Dataset consists of information about a few dozen thousands of unique items, but most of them are rarely sold and thus are presented with a statistically insignificant number of observations. Also, the total contribution of such items in the final revenue is rather small (up to a few percent). These facts were the reason that such records were excluded from the analysis. Instead, the main focus was made on forecasting the demand for top revenue-generating products. We focused only on the top 10 products. The visualizations that reflect revenue structure are presented below (Fig. 1-2).
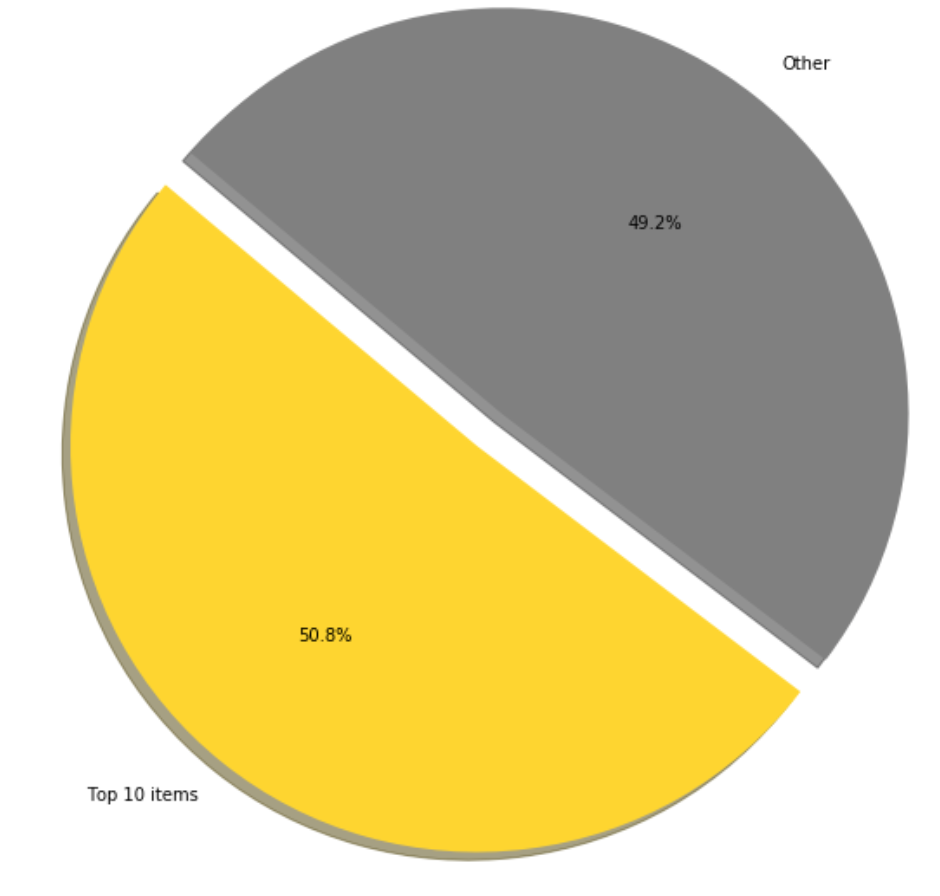
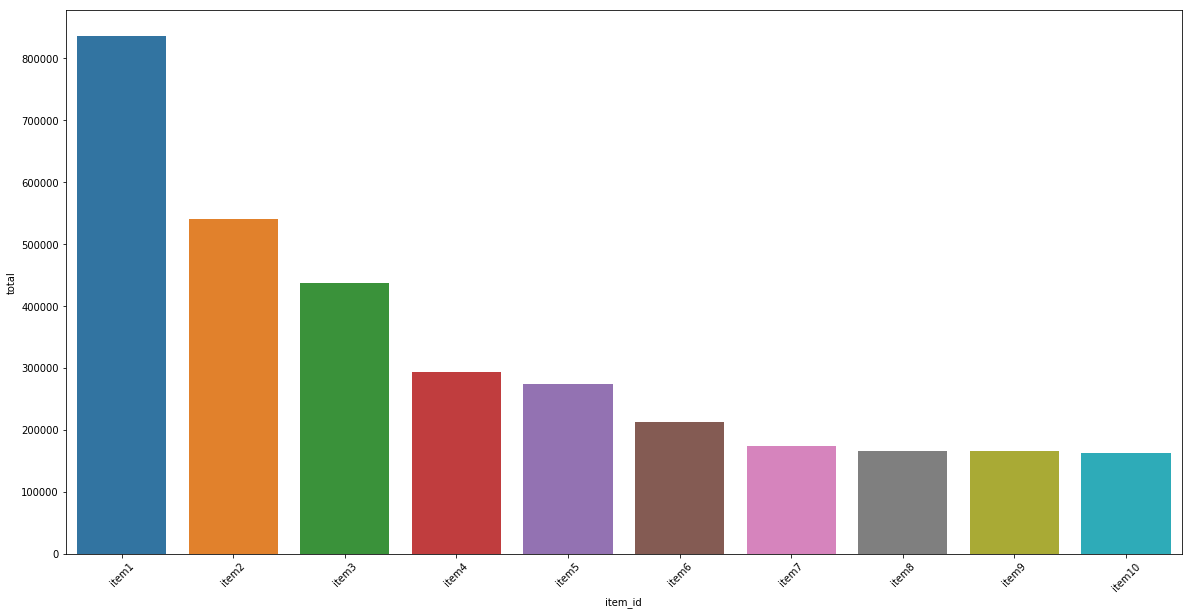
As follows from Fig. 1, more than half of cash flow is generated by the top 10 items, but deeper insights from Fig. 2reflects that the first 3-5 have a disproportionally bigger impact compared to the remaining ones. So it makes sense to have a detailed analysis for these particular products.
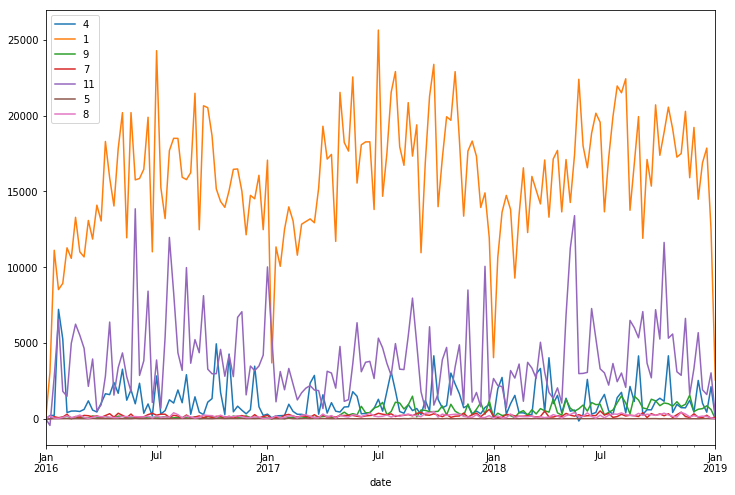
For a better understanding of the sales trends underlying nature, DataFrame was converted to a regular time-series, with timestamps along the x-axis and the amount in sales (in USD) along the y-axis (Fig. 3). As one can observe, there is a clear seasonal trend on a monthly level, repetitive during the analyzed time period. It is also worth mentioning that there is evidence of other repetitive trends, potentially of second and even third order. It looks that they are not very stationary, but still might be captured by AI models.
After exploitative data analysis was performed, some data engineering activities took place that correspond to phase 3. This stage doesn’t have a proper visualization as this research was performed on a high-quality data set and most of the phase 3 activities were related to anomalies detection and missing values handling. This results in dropping several hundred of suspicious or corrupted records.
Phase 4 was the most complex and time-consuming one, as it required lots of modeling and iterative experiments performed by the joint efforts of the data science team and business analysts. To prevent overfitting and provide reliable results data was divided into train and test subsets using a so-called time split. The underlying idea is the following: a particular point on the time axis is selected and data that comes before it is used as a train set, while the data that comes after is used for evaluation purposes. In the end, it was decided that January 1, 2018, will be split data. Thus, the system was trained on records from the years 2016-2017 and tested in the year 2018.
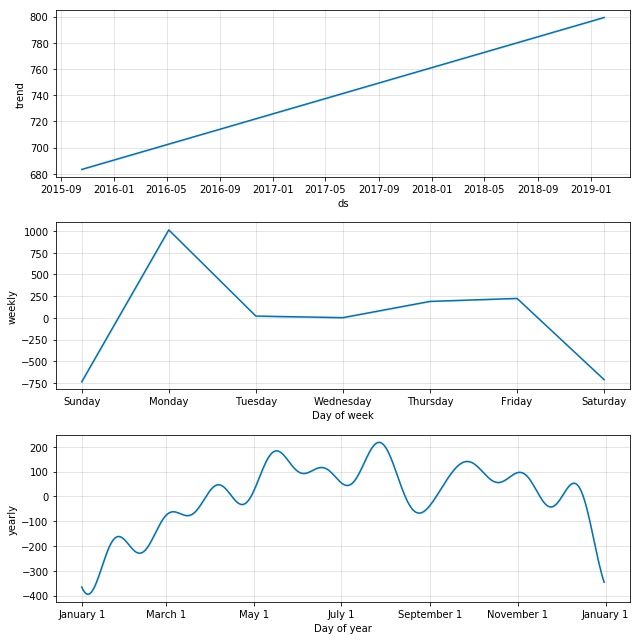
We have chosen three types of algorithms for modelling: ARIMA, Linear Regression, and Facebook Prophet. After multiple iterations and constant parameters fine-tuning, the ARIMA model was deemed best in terms of prediction accuracy and results explanation prospective. As follows from Fig. 4 below, the model was able to identify unique factors for various types of products that work as independent components, and final demand can be estimated as their interference. For the first item (Fig. 4a), it appears there are uprising trends over time that reflect the general long-lasting increase in product demand. While other trends are regular and reflect monthly and weekly seasonality in the sales process. However, for the second item (Fig. 4b) weekly trend is missing and the final demand is determined only by aperiodic market growth and periodic year trend plus monthly oscillations.
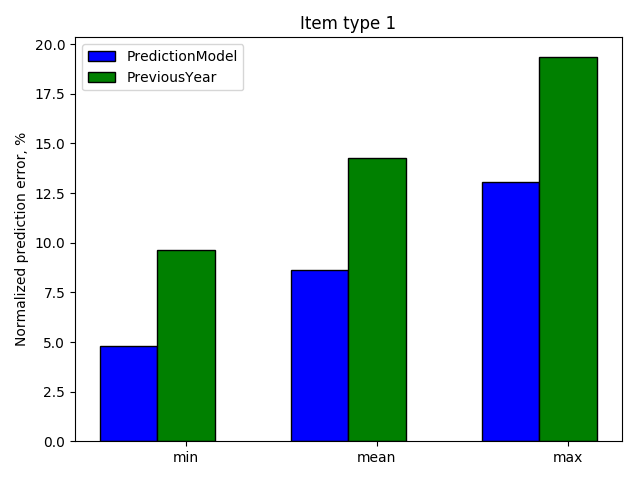
In terms of the achieved results, the developed AI-driven demand forecasting model was able to outperform the baseline look-up (shifted) model defined during phase 1 for all top 5 products, which on average resulted in 5% accuracy improvement which corresponds to a few million dollars annually (Fig. 5).
Discover how Advanced and Predictive Analytics can benefit your business – contact us by filling out the form below.