

Optical Character Recognition of Handwritten Numbers

OCR of Handwritten Numbers
Tax forms are used by taxpayers and tax-exempt organizations to report financial information to the government institutions. They are generally filled and saved electronically, however, in some cases filling by hand is necessary, e. g. if additional notes need to be added, or the input fields are too small for the electronic filing. Combined with loads of tax forms manually filled long before electronic returns became the norm they make up a considerable amount of documents that require digitizing. With this issue in mind, Abto R&D engineers developed an OCR technology able to detect, extract and recognize financial figures from tax return scans. The proposed handwritten numbers recognition technology enhances the processing of paper documents, increases productivity, and facilitates data mining.
Challenges of Handwritten Numbers Recognition
- Low quality of the tax return scans;
- Binarization effect of the scans;
- Unfavorable positioning of the digits inside the input fields when they cross or touch the lines of the tax return form;
- Resizing of the different length numbers that distorts the handwriting making it either too tight or too extended;
- Illegible handwriting that makes the digits indecipherable;
- Incorrect segmentation of the digits.
OCR Technology Development
Phase I. Preprocessing
Initial preprocessing of the tax return scans facilitates future digit recognition and is a crucial phase for delivering accurate results. In our algorithm it comprises several steps.
- Localizing input fields.
Our algorithm applies the scale-invariant feature transform (SIFT) to the blank tax form template and the tax return scan to find and extract the input fields from the latter. These fields contain relevant information – financial figures – we need to detect and digitize. - Rejecting empty fields.
An average tax return form has up to 65% of the empty fields. We discard them in order to optimize the OCR algorithm. - Normalizing identified numbers.
Different length numbers take different amount of space so we resize them to some unified scale. Now the preprocessed images of financial figures – handwritten numbers – are ready for recognition.
Phase II. Handwritten Numbers Recognition
First Approach: Classification
The most straightforward algorithm for text recognition is the classification of each character separately. However, due to the handwritten nature of the text we deal with, we needed to solve the segmentation task first. After training our custom classifier and recognizing each number one by one we have achieved 84% accuracy. Unfortunately, the average digit in the tax form contains 5 numbers so the recognition accuracy of the whole figure equals only 53%.
Second Approach: YOLO
We decided to train a You only look once (YOLO) object detection model for handwritten numbers recognition. But since YOLO technology it is originally developed for defining bounding boxes of the detected objects in colored images, it extracts a lot of redundant information we don’t need for our task. It is also computationally expensive and provides questionable accuracy of 73% as it recognizes some numbers partially (e.g. 8 is recognized as 3) or splits them in two (e.g. 8 is recognized as 00).
Abto Solution: CRNN
Abto R&D engineers managed to overcome all of the disadvantages experienced in previous approaches by building a custom Convolutional Recurrent Neural Network shown in Figure 1.
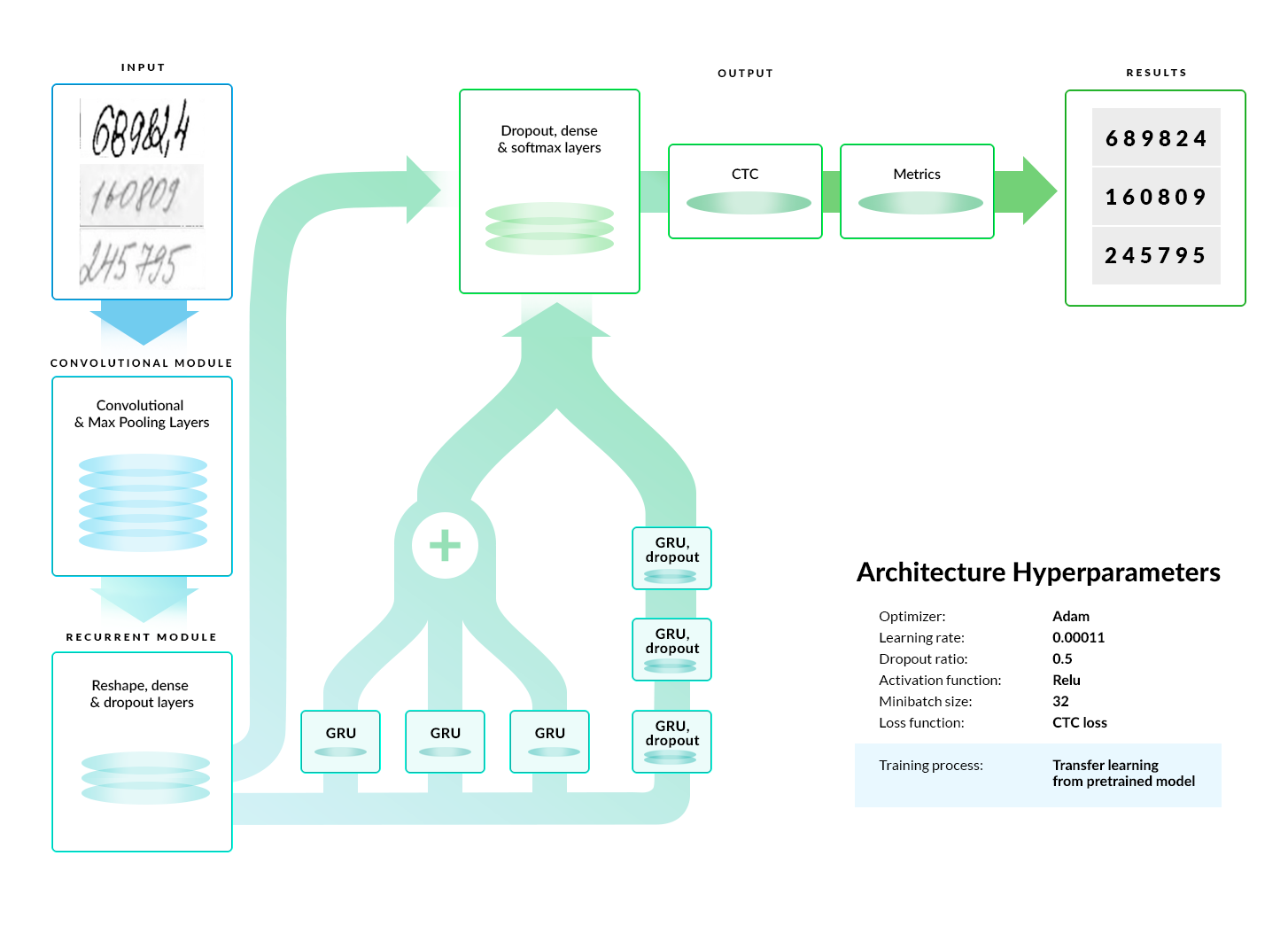
According to Abto custom architecture, the characteristic features are extracted from the handwritten text images using convolutional neural networks (CNNs). Extracted features are then fed into the recurrent module powered by recurrent neural networks (RNNs) which hold information about previously encountered and recognized text. A result produced by the neural network is a probability matrix that allows determining each handwritten character in the text sample. The average accuracy of such approach is 89% which as of August 2019 (time when we re-run the OCR experiments) was 2.5 times more than the accuracy shown by Google Cloud Vision API evaluated on the same dataset, as illustrated below.
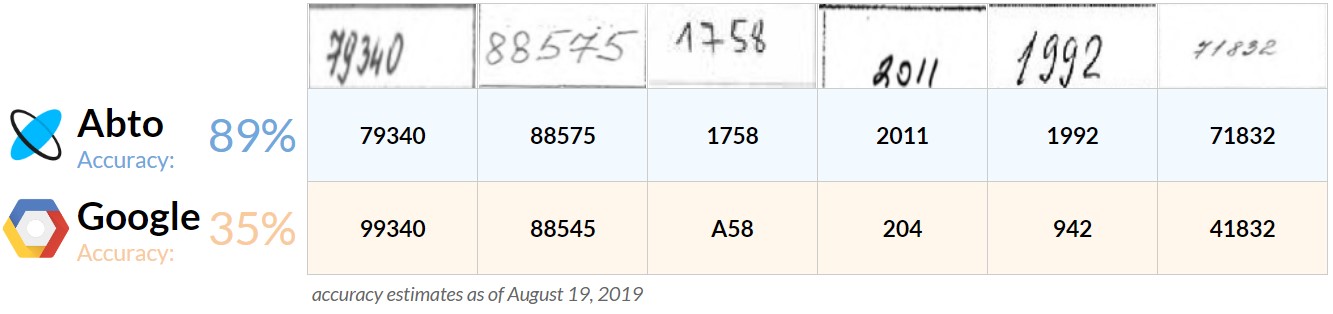
The increased accuracy of the Abto approach to OCR for handwritten numbers is reached, among other things, by adding dropout layers to the neural network and L2 regularization of the cost function that reduces overfitting and enhance the overall training process.
Technologies Behind Abto OCR of Handwritten Numbers
Abto technology for handwritten numbers recognition employs the next tools and technologies:
- Computer vision;
- Scale-invariant Feature Transform (SIFT);
- Convolutional Recurrent Neural Network (CRNN);
- Connectionist Temporal Classification (CTC);
- Gated Recurrent Units (GRUs);
- Deep learning;
- L2 Regularization.
Benefits of Abto Handwritten Numbers Recognition Technology
Our OCR technology for handwritten numbers recognition allows digitizing manually filled financial documents, so they can be electronically edited, indexed, searched, and processed. The benefits also include:
- time and cost efficiency: the documents can be stored more compactly or displayed online in any necessary format;
- increased productivity: extracted data can be used for the automation of financial processes and procedures;
- enhanced security and information preservation.
What’s next
We plan to integrate our technology into the mobile app so the user could upload a certain type of manually filled financial document and receive it in the electronic format with all of the numbers digitized by our technology. The user will be able to set “confidence rates” to achieve 100% accuracy – if the software does not recognize the handwritten number with the desired level of certainty, the user will be notified for manual review. We also plan to extend our technology to perform complex recognition of handwritten text.