


Image Pre-processing for OCR of Handwritten Characters
OCR (optical character recognition) is the recognition of printed or written text characters by a computer. This involves photo scanning of the text character-by-character, analysis of the scanned-in image, and then translation of the character image into character codes, such as ASCII, commonly used in data processing.
Many of today’s OCR systems are built following traditional approaches to image processing and work great with printed text but if use them for handwritten text recognition in images it can get unexpected results with poor recognition quality.
Here is a list of common problems that can occur while performing handwritten characters recognition:
- Complexity of characters separation from background
- Nonstandard (unique) form of symbols
- Nonlinear character location
- Different characters have different slope
- Neighbor symbols can be merged
- Some symbols can be not uniform
Therefore this task is much more complex than recognition of standard printed text.
Commonly OCR can be divided into two parts: pre-processing and extracted character recognition. This post will describe the problem of preprocessing images with handwritten characters and the issues that arise during the development of such algorithm.
Computer Vision Solutions
Give meaning to images, analyze video, and recognize objects with the highest accuracy.
Our R&D team has developed a Handwritten Text Detection prototype that processes even blurry, grainy and low-resolution images that was later enhanced to a comprehensive Data Extraction algorithm. It retrieves information in the key-value format and transforms documents into business-ready data better prepared for processing, analysis, and storage. You choose which keys to look for and the text recognition algorithm extracts data from all of the documents that contain indicated keys no matter where they are positioned within the document.
Before starting text recognition, an image with text needs to be analyzed for light and dark areas in order to identify each alphabetic letter or numeric digit. For that purpose, we need to provide preliminary image pre-processing. The pre-processing algorithm includes a few necessary and at first glance simple steps:
- Image binarization
- Waste clearing
- Text lines detection
- Character detection
I. Image binarization
The binarization process depends largely on image quality. In this case, will take a look at images with rather poor quality.
First of all, let’s make background averaging, using a histogram. For creating binarized images adaptive threshold algorithm will give us the best results. Here are the processed images after applying the algorithm:
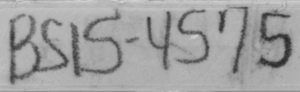 |  |
 |  |
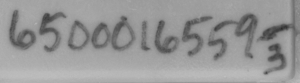 |  |
As you can see, not all images can be used for further pre-processing. However, if we use a few tricks from mathematical morphology (mathematical morphology is a theory and technique for the analysis and processing of geometrical structures) we could significantly increase binarization quality of those images. Modifying parameters of morphological functions for images with varying levels of quality will give us a better result:
 |  |
II. Waste clearing
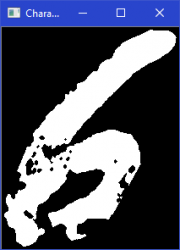
After completing the first step we have got binarized images, where groups of white pixels created characters and black pixels formed the background. But as you can see there is a big number of white pixels which are not part of characters, they have created blobs and noise that is highly undesirable for character recognition algorithm.
On the images below you can see the results of running waste clearing or waste filtering algorithms:
 |  |
 | |
 |  |
Looking in the pictures above, you can see clearly that the resulting images are not perfect, in some cases, the waste clearing algorithm can “eat” parts of characters, or skip unnecessary white pixels blobs. Still, these mistakes have small impact on the end result.
III. Text lines detection
One of the problems with handwritten text recognition falls on correct text lines detection. Since text lines are not exactly horizontal and often two neighboring lines can overlap each other, we will need to use slightly modified Hough algorithm on inverted images. The results you can see below. On those images two lines are dividing each picture into two parts with text lines. You can note that upper line cuts the lower text line and lower line cuts the upper.
 |  |
IV. Character detection
The last and the hardest step is character detection. I will try to describe it without going too deep into details. Let’s call our blob of white pixels which is a part of a character our region of interest, ROI. After completing all the previous steps we got some pre-processed pictures with defects. For example, some characters can be divided into parts or merged.
In the pictures below you can see how a problem with dividing single character was resolved:
 | |
 |  |
Resolving the problem with merged characters in handwritten text is harder. Because written characters have a very variable slope. Below you can see the results of characters division algorithm. Not all characters were divided correctly on this pre-processing stage because the software is not able to recognize what it is dividing.
 |  |
And the last step in character detection is character ROI separation and cleaning:
 |  |
 |  |
Conclusion
OCR of handwritten characters is a rather difficult task. For now, today’s software and developed algorithms can not achieve 100% accuracy (not even a real person can always recognize what was written). But OCR final result can be increased by iterating preprocessing-recognition sequence.
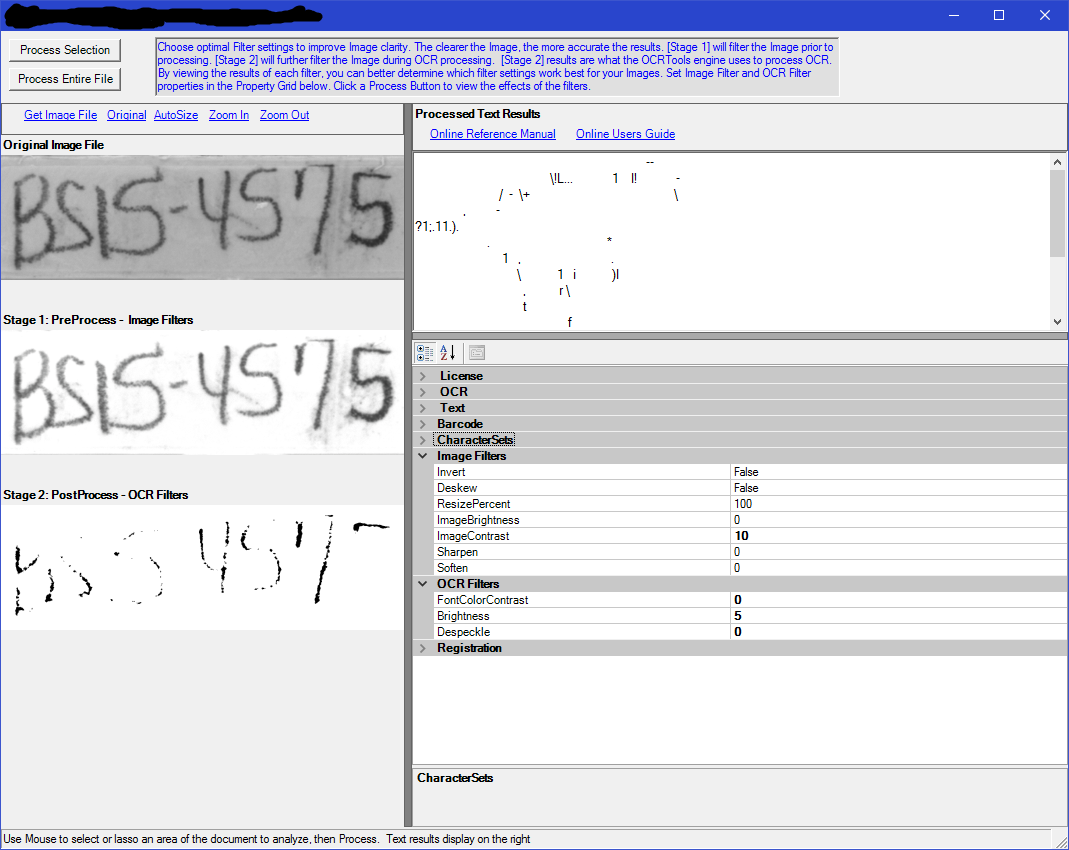
Using developed algorithms, we were able to achieve a pretty good level of accuracy. Some results you can see lower:
 | |
   | 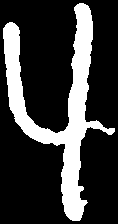    |
 | |
   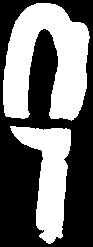  |     |
 | |
    | |
After conducting research for similar solutions we haven’t found on the market any available OCR software which could give us positive results on our test images. Most applications for handwritten text recognition still do not perform preprocessing correctly right from the start. To get better results, you will need to have some experience in the area to fine-tune this software.
We have tested a number of applications for OCR like ISkySoft, Online OCR service, FineReader, OCR Space to try and get better results, which you can see below:
For the development of our own software, we used Python and OpenCV.