
Intent recognition: the best chatbot framework

At Abto Software we needed to create an intelligent English and German-speaking chatbot for customer support and an intent recognition system for internal processes automation for one of our clients. That was needed to help the customer support department solve client problems in a faster and more efficient way by using natural language processing (NLP) techniques.
It turned out the client had a complex but fixed number of scenarios and end-user intents. So, the problem consists of two parts. The first is detecting end-user intent by their message text. And the second one is implementing the scenarios.
In this article, we’ll focus on the intent recognition part and compare chatbot frameworks to choose the one that will be best suited for this task.
The Challenge
There were several challenges in this project. The end-user messages were not so trivial. Sometimes the user says she wants to change the bank account number, and sometimes she only wants to change the way she receives invoices for her account number. So using simple keywords’ solution like “order”, “pizza” didn’t work, and we started looking for Machine Learning-based solutions.
The German language is relatively widespread (12th position) globally and especially in Europe. However, the number of resources for natural language understanding is limited. Many tools like Amazon Lex support only English. Also, the German language has lots of compound words, so subword analysis is required.
The client had strict end-user data security policies, so we couldn’t use online solutions.
The client was able to provide us with only about 1000 examples of training data. But the system needed to work with high accuracy and train progressively for multiple years.
AI-driven Chatbot Development
Empower communication with your customers.
Our Solution: Comparing Offline Chatbot Frameworks
Taking into account the challenge, we decided to compare the best available offline chatbot frameworks. Also, we implemented several relatively simple but efficient general text classifiers used for sanity check previously. Taking into account that intent recognition is a well-known problem, we also considered the top scientific papers on this topic from the list paperswithcode.com/task/intent-detection.
To make sure the chosen system will work best in the future when more data will be available we also used a big similar English dataset of combined ATIS and SNIPS. The language is different, so we had to make two versions of models with different word embeddings.
So, let’s describe the solutions we evaluated.
- Rasa framework has a set of config files to specify the data processing pipeline. We tested multiple options like:
- Rasa pre-trained spacy model with
de_pytt_bertbasecased_lganden_core_web_lgembeddings for german and English experiments - Rasa supervised model
- Rasa supervised model with
max_featureslimit – best of this group
- Rasa pre-trained spacy model with
- Our general text classification models:
- TF-IDF + logistic regression on manually created vocabulary
- SVM on top of ngrams
- xgboost on top of ngrams – best of this group
- Online learning experiments for fast continuous learning:
- logistic regression with partial fit
- creme logistic regression with count vectorizer
- creme passive-aggressive classifier with count vectorizer – best of this group
- DeepPavlov with adapted
intents_snips_big.jsonconfig which the authors recommend. Inside there is a shallow and wide CNN. We also tune the patience parameter for better train stability on our small datasets. - SF-ID-Network-For-NLU – the best neural network for ATIS and SNIPS datasets from the state of the art papers. We used
priority_order = intent_firstwhich showed better results probably because we don’t have slots in datasets. Also in the code, they use the test dataset for early stopping which is unfair, so we had to change this in the source code for more robust comparative analysis. Also, this means that the publicly reported score may be wrong and needs to be reviewed.
Testing on a bigger dataset was a good idea because it also showed that some systems were not designed for a bigger scale. We achieved out of memory errors for Rasa, SF-ID-Network-For-NLU and DeepPavlov. We had to limit the number of features for Rasa and reimplement a whole module to use sparse matrices instead of dense. Also for SF-ID-Network-For-NLU and DeepPavlov we had to cut the number of words in a message to one hundred.
Comparison Criteria for the Best Chatbot Framework Selection
First of all, we used two datasets:
- Proprietary German dataset with 700 texts with 4 intents (provided by the customer)
- Open English datasets ATIS and SNIPS datasets with 20314 texts and 25 intents
The simple default metric for this task is accuracy or the percent of correctly classified examples. But for our task, the F0.5 measure was more appropriate because we had “unrecognized” intent among others and precision was more important than recall.
Thus, three metrics were considered simultaneously:
- F0.5 for our German dataset
- accuracy for our German dataset
- accuracy for big English dataset
Results of the Chatbot Frameworks Comparison
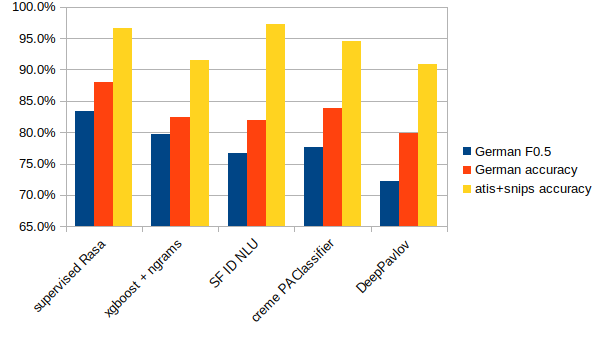
| German F0.5 | German accuracy | atis+snips accuracy | slots classification | online learning | issues | |
|---|---|---|---|---|---|---|
| supervised Rasa | 83% | 88% | 97% | yes | no | OOM bug, so need max_features limit |
| xgboost + ngrams | 80% | 82% | 91% | no | no | no |
| SF ID NLU | 77% | 82% | 97% | yes | no | OOM issue, so need max_words limit |
| creme PAClassifier | 78% | 84% | 94% | no | yes | no |
| DeepPavlov | 72% | 80% | 91% | yes | no | OOM issue, so need max_words limit |
The supervised Rasa model is chosen as best by all metrics, and it allows slots detection for the future. As mentioned above, the out-of-memory issue was also fixed. So now it’s completely reliable and can expect to achieve state-of-the-art quality in the future when more training data is available.
Rasa Supervised Model for Intent Recognition
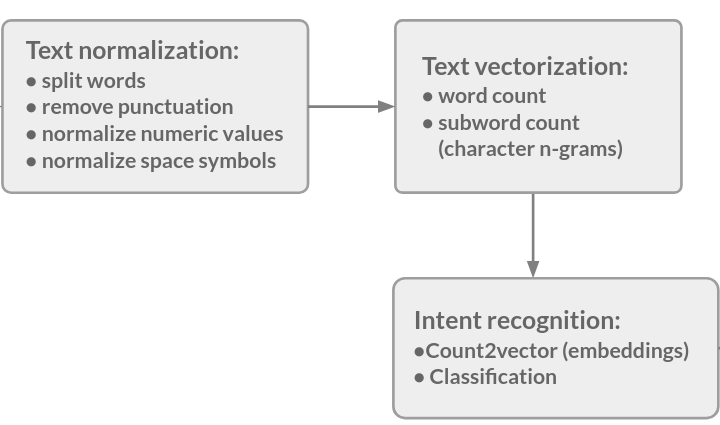
Let’s describe how it works. The main steps are shown in the diagram.
The authors say that char n-grams are the main features, and for our case of the German language they are even more important because of compound nouns. It’s interesting that labels are encoded the same way as texts. So the algorithm may have different quality if we rename labels, and the quality may be higher if we use similar names for similar labels.
The star space classifier is described in this paper. This algorithm embeds labels and texts with vectors of the same dimension and then compares corresponding texts a and labels b with cosine distance cos(a, b). Also, some non-corresponding labels bi are generated by negative sampling. They are also compared to text by cosine similarity cos(a, bi). Then the negative log loss of softmax of all these similarities cos(a, b), cos(a, bi)... is used as a loss function.
In the Rasa framework, they improve the original paper algorithm by inserting dense layers for achieving embedding vectors. Also, it’s interesting that batch size is incremented instead of learning rate decay during training.
Conclusion: the Best Chatbot Framework
We found out that Rasa is a good general chatbot framework and used it for both intent recognition and chat scenario parts. We had to reimplement the source code for our scale of data. Also, we used a model ensembling to further improve quality.