
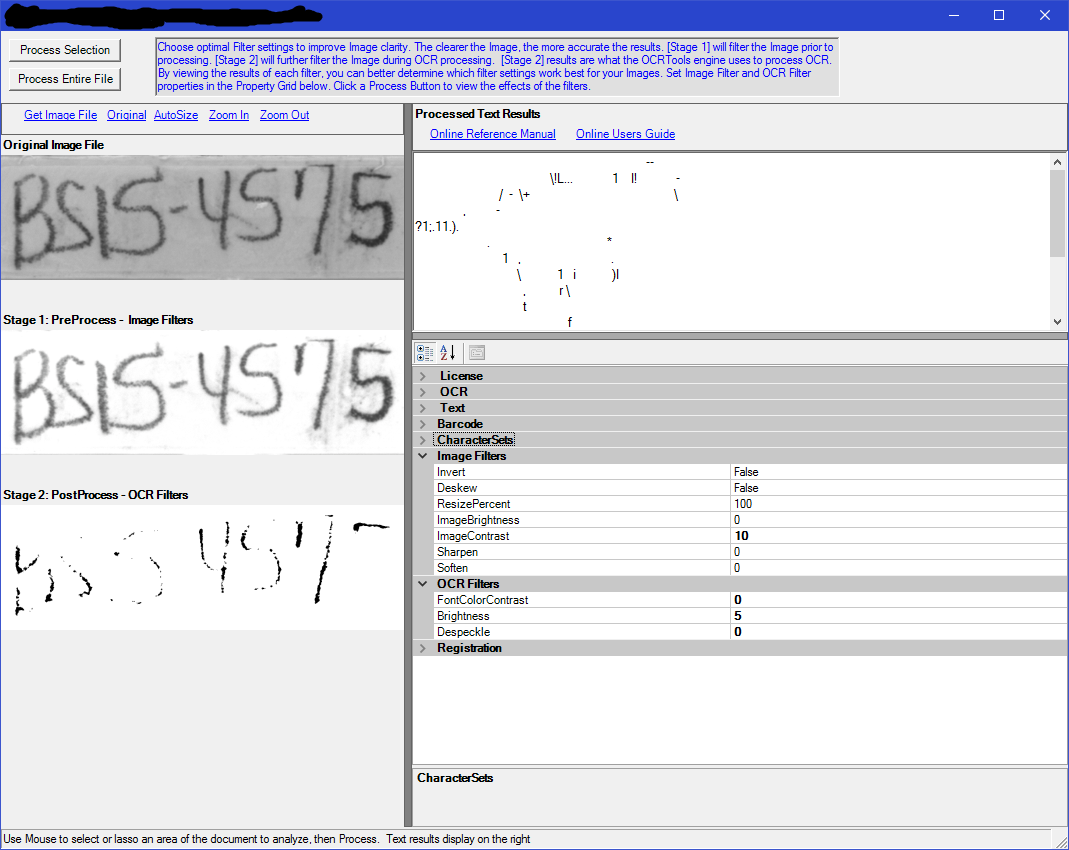

Review of Image Preprocessing Techniques for OCR

This article demonstrates different image preprocessing techniques with textual data which we consider useful for further OCR processing of said images.
These techniques can be easily combined into an image pre-processing system.
It should be noted that this report is mainly a quick review of what can be done. All the demonstrated image preprocessing techniques can be further enhanced for the sake of achieving even greater accuracy/performance.
Our R&D team has developed a Handwritten Text Detection prototype that processes even blurry, grainy and low-resolution images that was later enhanced to a comprehensive Data Extraction algorithm. It retrieves information in the key-value format and transforms documents into business-ready data better prepared for processing, analysis, and storage. You choose which keys to look for and the text recognition algorithm extracts data from all of the documents that contain indicated keys no matter where they are positioned within the document.
Image alignment
Proper image alignment that puts text in the image into position close to upright significantly increases an accuracy of the further OCR processing. Image alignment includes different types of transforms, such as affine transform (rotation and deshearing/deskewing), perspective transform and others. Here we demonstrate an application of the affine transformation to the image as it is the most useful type or preprocessing. Below we demonstrate steps that produce aligned the image with some comments. For further comparison, the source image was taken from ImageMagick website.

Fig. 1. Source image A – an easy case for binarization.
We perform alignment by applying our custom-developed algorithm to the image. Depending on the image resolution, the final rotation of the image differs from the true upright angle by no more than 0.01 rad in the best case.

Fig. 2. Image rotation result.
We then binarize the image (using Otsu algorithm) and remove some small binary noise. Source image A represents an easy case for this step, results are shown below.

Fig. 3. Image A, binarization results.
Source image B has much higher levels of noise of different types caused by non-uniform illumination and scanning artifacts. This image was also taken from ImageMagick examples.

Fig. 4. Source image B – lots of noise.
To remove this noise we must separate the text itself from the background. We developed an algorithm that produces a probability map of every pixel being text (and not noise). Figure 5 demonstrates this in a form of a greyscale map of interest, where we marked all the lightest pixels as a part of the text.
We then use this map to obtain the mask of the text areas, as shown in Figure 6.
Finally, figure 7 demonstrates the result of the application of this text mask to the source image.

Fig. 5. Probability map.

Fig. 6. Text areas mask.

Figure. 7. Source Image B cleaned.
We’d like to note that the text on the source image B is in French and contains a lot of characters with diacritic symbols, preserving which is essential for high-quality OCR. As demonstrated, our approach preserves a very significant percentage of diacritics. As a comparison, we’ll provide the result of ImageMagick’s denoising of the same image (fig. 8). Note how a lot of diacritics are lost in the process of denoising. As demonstrated, our approach preserves a very significant percentage of diacritics.

Fig. 8. ImageMagick’s denoising of source image B
Scan line removal
Scan images usually have scan artefacts in the form of scan lines. To simulate scan lines and other such noise we picked an image (source image C) with non-uniform illumination, moiré and screen-door noise (caused by black areas between display pixels).
Fig. 9. Source image C.
We start by building a map of artefacts that later will be used for precision binarization.

Fig. 10. Map of noise/artefacts.
Fig. 11. Inverted source image C, binarized and aligned.
Upside-down orientation detection
Last but not least, we demonstrate the application of our custom-developed algorithm for upside-down text orientation detection. Fig. 12 shows the result of the application of this algorithm to a set of randomly chosen chunks of text of different origin (different languages and alphabets). Green areas depict proper text orientation, while red ones show the chunks where the text is upside down.

Fig. 12. Upside-down orientation detection.