


GPT‑5.3-Codex vs. Claude Code: a comparison

Recently, Anthropic released Claude Opus 4.6. Within the same hour, OpenAI released GPT-5.3-Codex. Let’s compare them by writing a small website. The website will be trying to demonstrate one interesting psychological phenomenon.
To avoid spoiling the effect, let’s try it on you first.
Think of a random number between 1 and 100 and write it down or remember it.
Now, the second question for you is to estimate the number of African countries that are members of the United Nations.
Now, the anchoring effect is the fun fact that even though the first number was completely random and in no way related to the number of African countries in the UN, your second answer will be tied to the first number that you thought of. For example, if you chose 78 as your first random number, you might think that the number of African countries is higher, and if you chose 13, you will think of a lower number. If you don’t believe it, you can write a small website to test it on your friends, family, and colleagues.
Claude Code
Here is a prompt that we used, which you can easily repeat with your favorite artificial friend:
“I need to write a small application that will check the priming effect. This should be a website. The first question will be to enter a number between one and one hundred. It should have some validation to prevent entering any other numbers or letters. The second question will ask how many African countries are members of the United Nations. This question should have validation for a number between zero and one thousand. It should remember the answers and prevent submitting more than one answer per browser session. Then, for admin mode, it should provide statistics on the answers provided. It should show a graph with answers one and two. The X-axis will be a participant. The Y-axis should show answer one and answer two. There must be two plot lines, one plot for answer one and another plot for answer two. Also, suggest some correlation analysis between those answers to confirm or deny the hypothesis that answer number two will be correlated with answer number one. Generate some random test data that can be filled from the admin mode. Also, admin mode should allow starting a session and closing a session. When a session is open, it must allow entering answers, and when it is closed, it must not allow submissions. Let there be a history of sessions.”
We will start with the Claude extension for Visual Studio Code. The first thing is to switch to the planning mode, where it will just plan what we need to do instead of writing right away. Even though we told it to write a website, it starts with exploring the directory to find existing files. Luckily, we can interject its flow when it asks to list the files and instead just give a custom answer that there are no existing files, no structure, and that we really need to write a new website.
Then, when answering its question about our preferred tech stack, we’ll try to hint that we will need free hosting for it.
After exploring a number of options, it chooses the following tech stack:
- Backend: Node.js + Express
- Database: SQLite via better-sqlite3
- Frontend: Vanilla HTML/CSS/JS + Chart.js (CDN)
- Auth: express-session with single admin password
- Free Hosting: Glitch.com (persists SQLite in the .data/ directory, free HTTPS, no credit card)
That will be its first glitch, because the Glitch.com homepage says “Until We Meet Again” and talks about ending support for project hosting on Glitch.
Claude didn’t believe that sad news at first and went to verify it, and then found alternative free hosting options for Node.js with SQLite. At this point, we nudged it to use Next.js with Supabase, Vercel, or similar.
It agreed on Vercel plus Supabase, while also suggesting a secondary option of Vercel plus Neon Postgres, recommending Supabase as it has a more generous free tier (500 MB vs. Neon’s 0.5 GB). Wait, what? Let’s call it out on that comparison and just for fun try Neon.
Our final tech stack:
- Framework: Next.js (App Router)
- Hosting: Vercel (free hobby tier)
- Database: Vercel Postgres (Neon) – all on one platform, auto-wakes on queries
- Frontend: React + Chart.js (via react-chartjs-2)
- Auth: Simple admin password via server-side API routes + httpOnly cookies
- All DB credentials server-side only – the browser never sees database connection strings
Finally, our plan is approved, the TODO is written, and Claude starts writing the code.
It does “All math implemented from scratch – no external stats library needed,” which bites us later.
During implementation, it realizes that “The @vercel/postgres package is deprecated in favor of Neon’s SDK. Let me update to use @neondatabase/serverless instead.” As we have Context7 MCP configured, it is used for getting the latest information about the Neon library and updating the code accordingly.
A small gripe is that even though it has access to Context7, it used Next.js version 15 instead of the newest version 16.
Then it builds, fixes a minor error, and provides us with short instructions on how to deploy and run locally. Finally, we ask it to generate a CLAUDE.md file to be able to continue in new chats and save tokens.
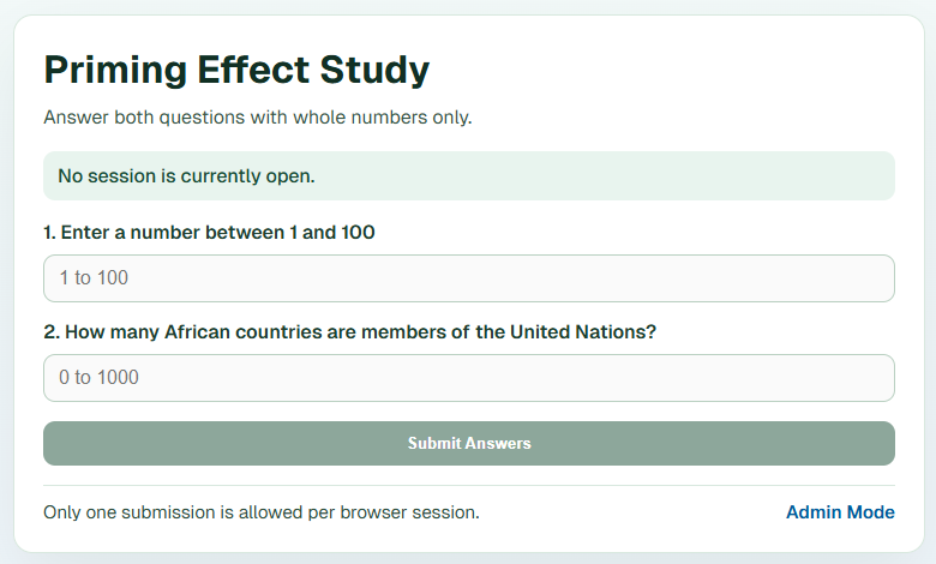
The result looks good. A clean survey page with two questions, one after another, basic checks to not submit multiple answers, and basic auth.
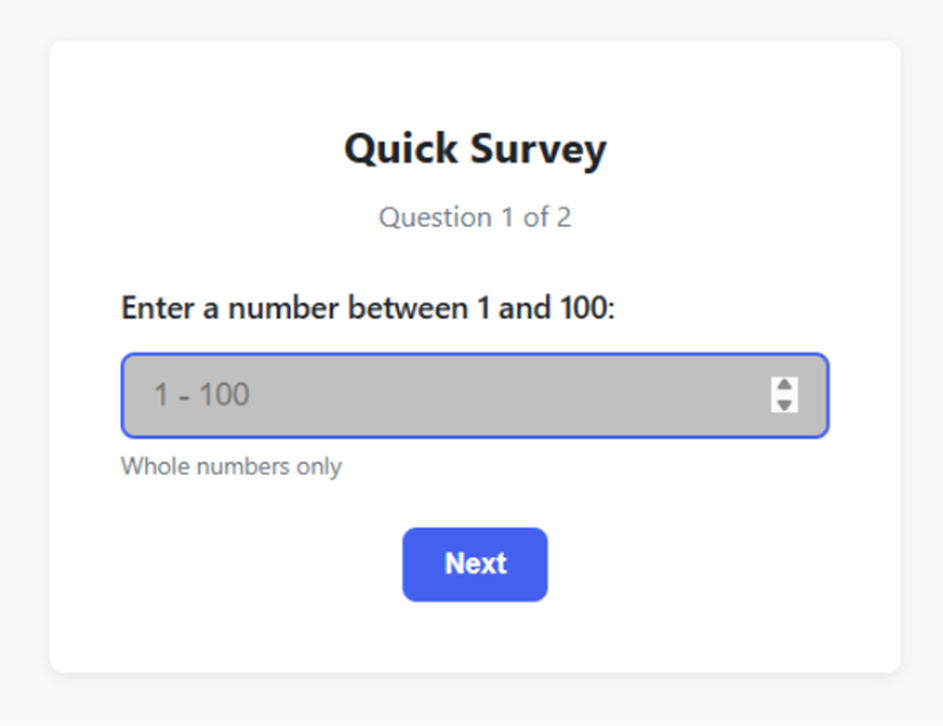
Claude Code first question survey page
Though remember, it implemented all math from scratch. Unfortunately, the p-value is 19,326,967,569,547, which is quite a bit bigger than the usual threshold of 0.05. That is suspicious – maybe that calculation is wrong.
Pointing this out to Claude, it fixes and tests the algorithm, then adds those tests to the source code.
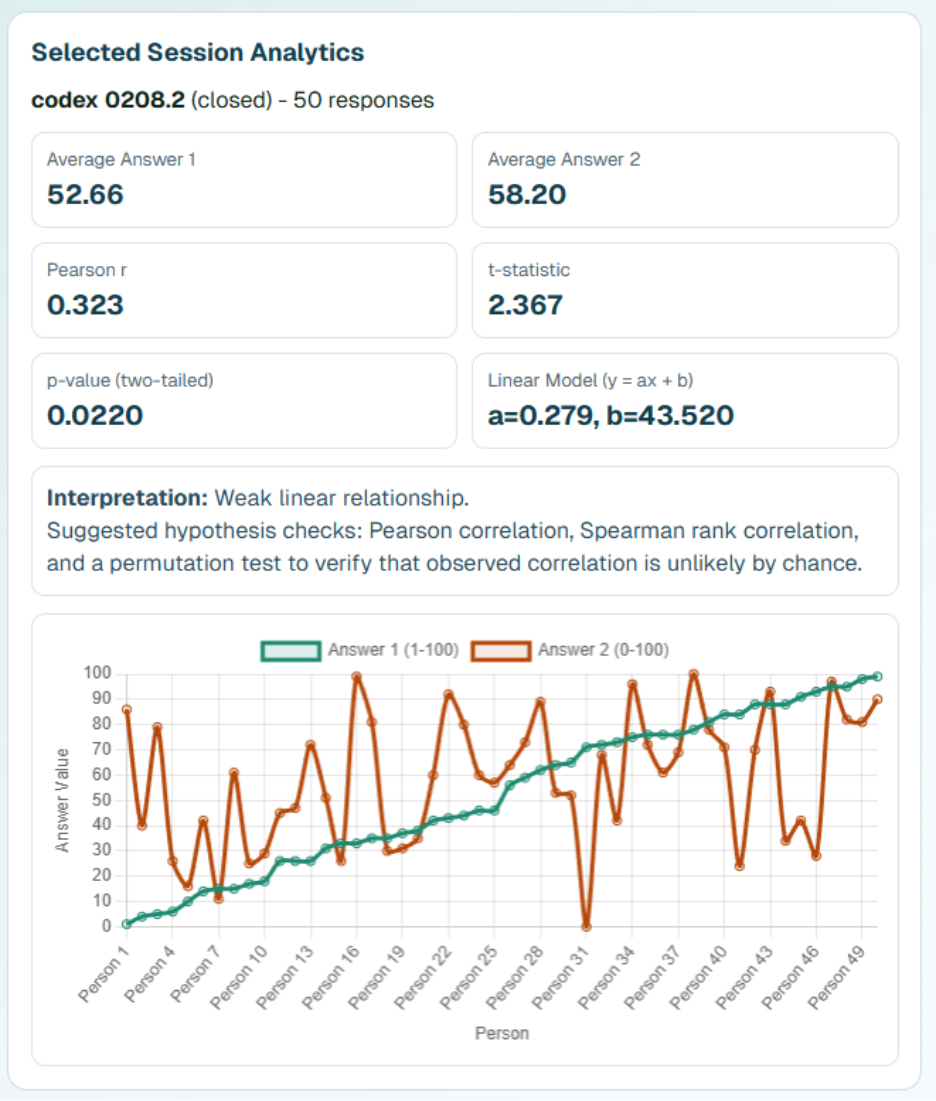
Later, small changes are applied correctly – for the responses chart, participants are sorted by the value of q1 (chosen number); the second question upper bound is increased from 1000 to 100.
Overall, the Admin page is fantastic. Informative results, two charts, explanations, and visually compelling output.
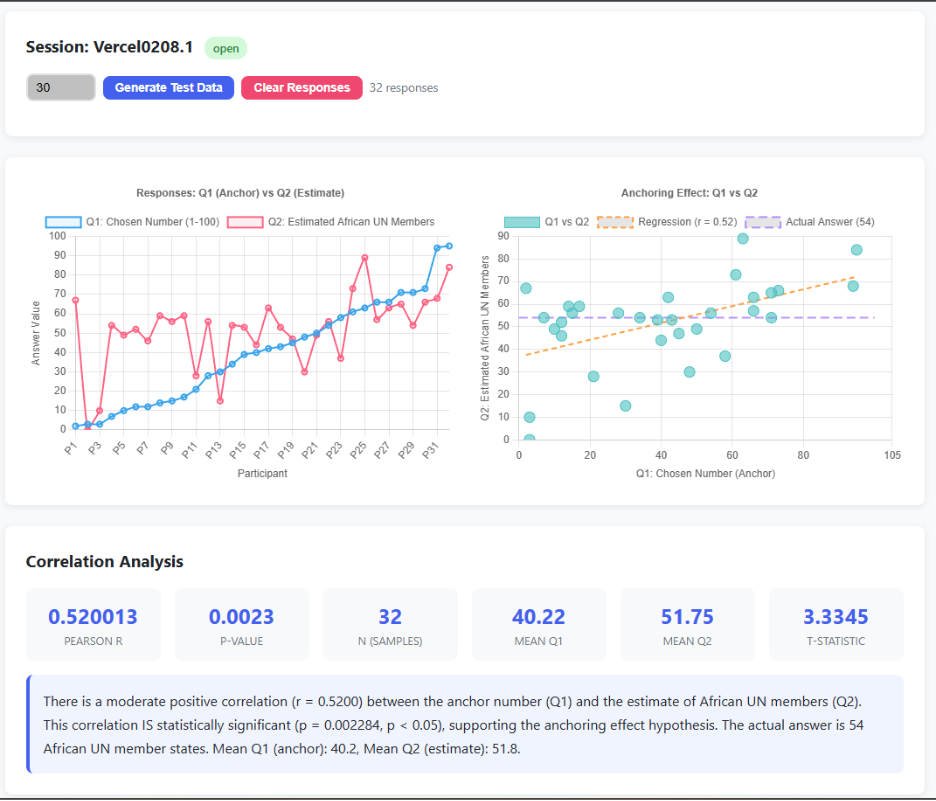
Claude Code results dashboard
GPT Codex
Now it is time to put GPT Codex in VS Code to the test. We will be using GPT-5.3-Codex with high reasoning. Starting from the same prompt, we go through the known steps. It tries to find an existing project in the folder, then suggests a Node.js/Express/SQLite site. When asked for hosting, it suggests Render/Railway/Fly.io, but then warns us about “Important constraint: If you keep SQLite, avoid platforms with an ephemeral filesystem (or serverless-only patterns), otherwise your study data can disappear. If you want, I can adjust the plan to Postgres so it can run cleanly on Vercel/Netlify backends too.” Then we nudge it to use Next.js and Neon to be able to compare with Claude.
- Build a Next.js app (App Router) with:
- Vercel API/Server Actions for submit/admin operations
- Use Prisma with Neon
One tech stack change is that it uses the Prisma ORM (which is more robust), while Claude used simple SQL queries (which are suitable for such a small website).
When it writes code and asks for confirmation, the diff window is small and it’s hard to track changes. Clicking the link to the file just shows the current state.
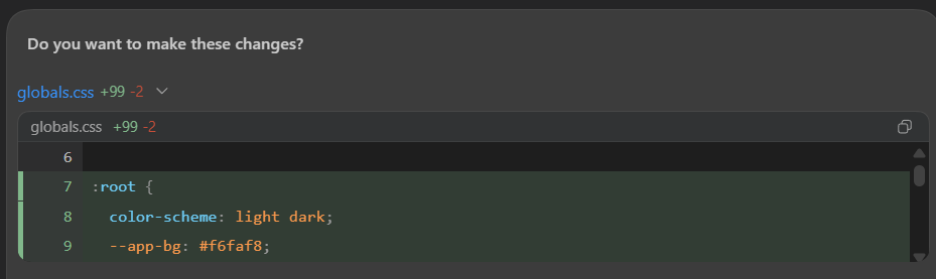
GPT Codex diff dialog
In Claude it is possible to expand the window to review full changes:
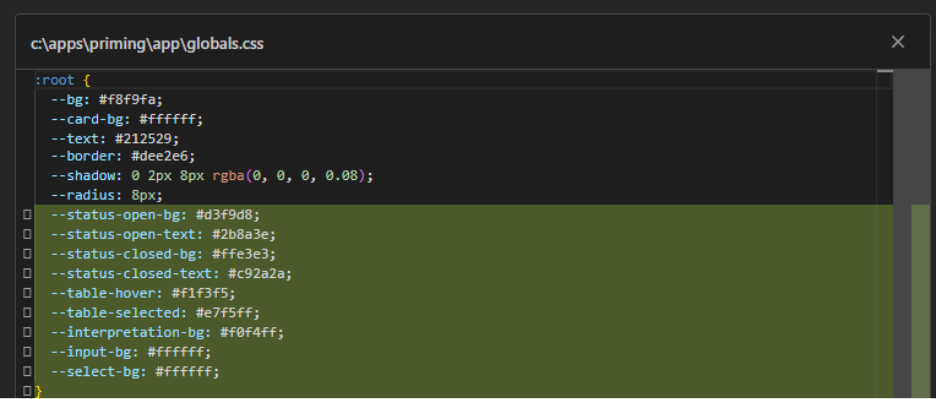
Claude Code diff dialog
During the sessions Codex hung up a couple of times, for example when it tried to prepare summary, started 8 subtasks to read changes from files and waited for confirmation from a frozen UI – restart was needed.
In general, chat formatting is just a tad less polished and easy on the eye than Claude’s formatting.
GPT Codex:
GPT Codex short summary on what was done
Claude Code:
Claude Code short summary on what was done
Then we have the result:
GPT Codex survey page with two final questions
It’s visually good, and it has a link to Admin Mode and back (Claude told us to go to /admin manually).
Stating to participants that the study is about the priming effect and presenting both questions at once goes against the “blind test” principle of experiments. We wouldn’t hold that against GPT; it is rather that Claude was understanding the business logic more deeply. Note that our prompt says “priming effect”, because originally, we mixed it with the anchoring effect, which is actually tested. To be more impressed with Claude’s thinking – it understood the mix-up and labeled the chart in the Admin dashboard as “Anchoring effect.”
The Admin page is also great, too dark for our taste if we’re splitting hairs. Only one chart (we also needed to ask to sort it by the first answers). Also included an interpretation – without details. It didn’t add a p-value and t-statistic, but when asked, it added them without errors, which is the most significant win over Claude. When generating test data, it provided two options – correlated and independent – good thinking in this part.
GPT Codex results dashboard
Summing up
In our little experiment:
- Claude Code has provided a better user experience
- GPT Codex is perhaps a little rough around the edges
It would be preliminary to make blanket statements about which is better or should be preferred by engineers. Both did very well and wrote a website that ran without errors on the first go.
If talking about reasoning:
- Opus 4.6 has provided a better business-logic understanding
- GPT-5.3-Codex High has excelled at accurate math calculations
The takeaway is that they are both definitely worth trying in your daily work to foster some creativity at least.