Interactive learning powered by AI and RPA technology
Project summary
A unique AI- and RPA-backed solution that transforms traditional tutorials into interactive learning experiences. By combining LLMs with RPA technology, the platform turns instructions into guided, clear demonstrations where users can interact through both voice or text commands while watching tasks performed in real-time.
Research shows that organizations that use e-learning technologies can reduce training time by 40–60%.
Services:
Brief overview
From Passive Reading to Active Learning, traditional tutorials often fall short by being static and disengaging, relying heavily on text and images. This demo introduces a groundbreaking tool that reimagines tutorials as dynamic, interactive experiences.
By leveraging Large Language Models (LLMs) and Robotic Process Automation (RPA), we create an immersive, hands-on learning journey that bridges the gap between instruction and execution.
More about leveraging AI for creating a complete interactive learning tool to revolutionize e-learning.

The problem
The Limitations of Traditional Tutorials:
- Static and unengaging formats lead to poor retention
- Users struggle to follow complex instructions without visual aids or step-by-step guidance
- Lack of interactivity prevents users from clarifying doubts or exploring beyond the predefined scope
Train users 5x faster


The solution
The use of both RPA and AI in e-learning allows users to:
- Engage with tutorials using text or voice commands
- Watch tasks performed in real-time within a simulated environment
- Learn more effectively with hands-on guidance and visual feedback
Key features
- Interactive Dialogs
a. Users can navigate between tutorial steps or ask for additional explanations
b. Explanations are delivered via text or voice for a personalized learning experience
- Real-time Visualization
a. An RPA player performs actions described in the tutorial, such as highlighting and clicking buttons
b. Users learn by watching tasks unfold step-by-step
- Screen Recognition with Computer Vision
a. Automatically detects UI elements like buttons or menus in application screenshots
b. Enhances accuracy with coordinates and bounding rectangles for interaction
- AI-Powered Step Generation
a. LLMs analyze tutorial text to create detailed, step-by-step instructions
b. Automatically generates RPA scripts to replicate tasks interactively
Practical example
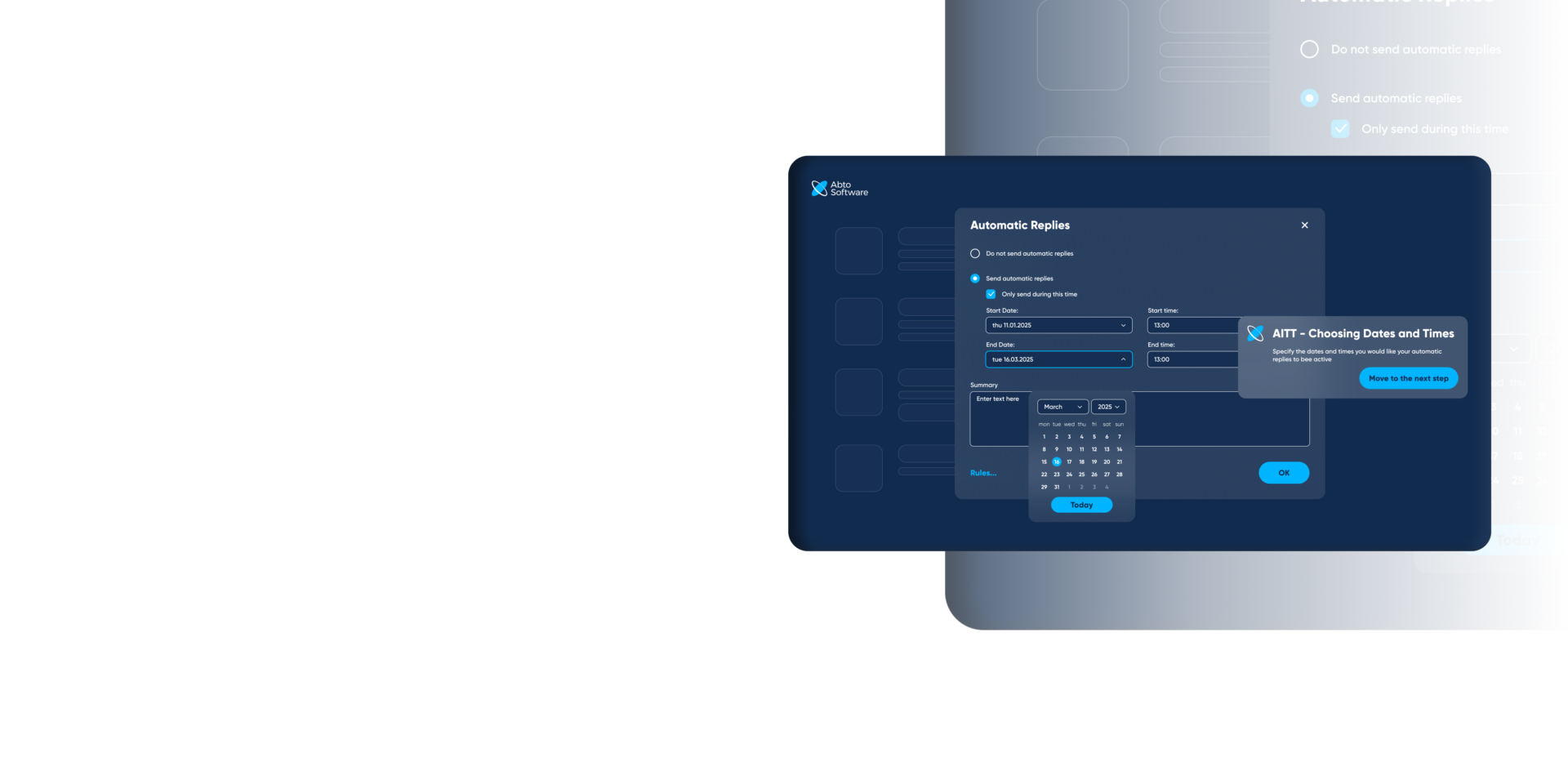
Microsoft Outlook Auto-Reply Tutorial
Imagine learning to configure auto-reply to emails in Microsoft Outlook. Instead of reading a static guide:
- You interact with the tutorial, asking for clarifications.
- The RPA player highlights the “Settings” button, clicks it, and guides you through the process in real-time.
- Computer vision ensures UI elements are accurately recognized, making the process seamless and intuitive.
How does it work
Technical architecture
1. RPA Engine
Our custom micro-RPA engine is designed for attended automation and supports essential actions required to automate tutorials. These commands facilitate interaction with UI elements, capture visual data, and coordinate events. The RPA automation logic is encapsulated in a JSON file generated from the tutorial text. Key actions include:
- Get Window Handle Action: Locates the application window by identifying its unique reference (“window handle”) to ensure readiness for interaction.
- Capture Screenshot Action: Captures the application’s screenshot to analyze and identify relevant UI elements.
- Detect Coordinates Action:
– Dynamically identifies UI elements using image recognition or text detection, accommodating variations in screen resolutions, DPI settings, or interface configurations.
– Processes graphical icons with image cropping and template matching for precise identification.
– Utilizes OCR (Optical Character Recognition) for text-based UI interactions, even from dynamic content or screenshots. - Highlight Area Action: Visually emphasizes UI elements or areas of interest to guide the user during the tutorial.
- Delay Action: Introduces intentional pauses to synchronize actions and accommodate UI load times.
2. Input
The user provides a URL (e.g., Microsoft Outlook documentation for setting up an auto-reply message). The system extracts the tutorial content from the URL or structured data containing the necessary steps.
3. Tutorial Content Pre-Processing
Tutorial content undergoes pre-processing to minimize text size and optimize it for LLM input. This involves:
- Extracting Text: Text is extracted from the body element of the DOM.
- Removing Redundant Data:
– Base64 Image Representations: Base64 image data is replaced with temporary image IDs. The original images are stored in a memory dictionary, where the image ID serves as the key, and the Base64 representation is stored as the value for further processing.
– Image Links: Image URLs are replaced with temporary image IDs. The original images are stored in a memory dictionary, with the image ID as the key and the image URL as the value for subsequent processing.
4. LLM First Pass – Analysis
The first pass analyzes the tutorial content to extract meaningful instructions:
- A targeted prompt guides the LLM (e.g., OpenAI) to parse the tutorial into specific steps, commands, and instructions.
- Content is structured into a fixed format with steps, commands, and descriptions.
5. LLM Second Pass – JSON Generation
The structured tutorial content is converted into JSON:
- A comprehensive prompt ensures the LLM generates detailed and actionable instructions.
- Steps are mapped to discrete actions (e.g., “click a button,” “enter text”) in a structured JSON format.
6. Enhancement
Once the RPA automation JSON is generated, the enhancement process ensures accuracy. During this process, the user may enter the “Enhance Automation” flow, where:
- The RPA script is executed sequentially by the RPA Player, which visually performs each tutorial action step by step.
- After each action, the user is prompted to confirm if it was accurate and understandable. If the response is positive, the process moves to the next action.
- If the response is negative, the user can enhance the automation by manually identifying the incorrectly detected element on the screen and capturing additional details for the RPA engine. These enhancements might include:
– Defining a more precise UI selector to improve accuracy and performance.
– Capturing a screenshot of the relevant element, enabling the RPA engine to leverage computer vision techniques to identify the UI element during runtime across different screen resolutions and DPI settings.
– Providing additional context for the user - The user iteratively refines the automation using this enhancement flow until satisfied with the results, after which the enhanced automation JSON is saved.
7. Execution
The interactive RPA Player brings the tutorial to life:
- Executes the action sequence step-by-step with real-time visualization
- Handles user inputs (text or voice), enabling dynamic interaction and clarifications
- Provides a seamless, immersive experience with actions executed in sync with the tutorial content
8. Output
- The tutorial execution delivers real-time feedback by visualizing actions like button clicks, text inputs, and menu navigation
- Interactive elements powered by LLM allow users to request additional guidance, ensuring a tailored and effective learning journey
This base-level design lays the foundation for future enhancements, enabling support for a broader range of use cases and additional functionality. By transforming passive tutorials into active learning tools, this architecture redefines how users engage with instructional content.
Key concepts and techniques
1. Window Handle
A window handle is a unique identifier for an application window in a graphical user interface (GUI). This is used to ensure that the automation script interacts with the correct window during task execution. In non-technical terms, it’s like a name tag for a window to tell the system which app or browser window it needs to control.
2. OCR (Optical Character Recognition)
OCR technology converts text in images (or from screenshots) into machine-readable text. It’s useful for detecting and interacting with text-based UI elements, such as labels, buttons, or instructions.
3. Image Recognition and Template Matching
This technique is used to identify images or graphical elements on the screen. It’s based on comparing portions of an image (like an icon or button) with pre-existing templates or patterns to find the matching element.
LLM prompts
When crafting prompts for a Language Learning Model (LLM), the primary goal is to provide clear, concise, and unambiguous instructions that guide the model’s behavior effectively. To achieve this, we incorporate the following strategies:
Explicit Instruction Design
The prompt includes precise guidelines on interpreting the tutorial content. This ensures that the model understands not only the scope of the task but also the format and style of the expected response. For example, if the task requires generating output in a specific format (e.g., JSON), the prompt explicitly outlines the structure, including action types, property names, and value formats.
Example-Driven Clarity
To fine-tune the model’s understanding, we provide it with well-defined examples of correct outputs. These examples serve as a template or reference, enabling the model to generalize its responses for similar tasks effectively. By illustrating the desired response format, the examples reduce ambiguity and improve the model’s adherence to the task requirements.
Iterative Prompt Refinement
Prompts are iteratively tested and refined based on the model’s output quality. This involves analyzing the responses to identify areas where instructions may be unclear or misinterpreted and subsequently enhancing the prompt to address these issues.
Robust Error Handling and Edge Cases
The prompt anticipates potential ambiguities or edge cases that might arise during the task. For instance:
- When providing JSON output, we specify how to handle missing or incomplete data fields.
- We include fallback instructions, such as “return a placeholder if no matching content is found.”
Stateless Operation Adaptation
Since the LLM processes input in a stateless, one-time, request-response manner (i.e., it does not retain memory of past inputs or interactions), we design each prompt to be self-contained. This involves:
- Repetition of Context: Embedding all necessary background information and context within the prompt itself.
- Clear Task Segmentation: Breaking down complex tasks into smaller, independently executable instructions to ensure that each request is manageable and comprehensible in isolation.
Tutorial Analysis LLM Prompt example: see analyze-and-structure-tutorial.txt
JSON generation LLM Prompt example: see generate-tutorial-schema-prompt.txt
Turn expertise into repeatable, self-teaching tutorials
Business value
This interactive tutorial tool redefines how users learn and perform tasks, making the process intuitive, engaging, and effective. Whether you’re teaching software navigation or complex workflows, this technology turns every tutorial into an interactive journey.
The showcased demo serves as a proof of concept for the innovative idea described above. It lays the foundation for future enhancements and extensions, enabling us to tackle even the most complex use cases and scenarios. By harnessing the combined power of RPA and AI, this approach has the potential to revolutionize how daily tasks are automated and streamlined.
The use of both RPA and AI in e-learning promises:
- Enhanced Engagement: Users actively participate in the learning process
- Improved Retention: Visual and interactive elements make learning stick
- Faster Mastery: Hands-on demonstrations reduce learning curves
- Scalable Solution: Works with any tutorial text and supports diverse use cases