


Image-to-Image translation

Interested how sophisticated algorithms can turn the same winter landscapes into realistic summer photos? Keep reading.
Abto Software’s R&D engineers conducted comprehensive, meticulous research to investigate the possibilities of modern machine learning and the output quality it can potentially provide for translating winter landscapes into accurate summer photos.
We covered the research and investigation of different generative models and algorithm application methods. With a solid dataset, we adopted the most suitable model to handle the challenges associated with such a complex project.
We see the opportunities of transitioning winter photos in benefiting landscape design and some related areas. This way, landscape architects and designers could see clearer how, for example, snow-covered landscapes could possibly look like in all other seasons.
Conditional generative adversarial network
We examined and tested various models and methods, including CGAN, CVAE, and pixel-to-pixel translation. The CGAN – conditional generative adversarial network –, an extension to GAN, has shown to be the most suitable approach for the set task.
Its advantages can be reduced to:
- Sharp and realistic synthesis of images
- Excellent match for high-dimensional visual data
- Semi-supervised learning
- Bleeding edge computational technology
The CGAN is simply an extension to GAN that involves conditional generation of images by a generator model. The generative adversarial network is a ML framework commonly utilized to train generative models that relies on a generator designed to create new images, and a discriminator used to distinguish synthetic images.
By adding additional details, we receive faster convergence, which creates some patterns even for fake images. Another thing, this approach helps control the output by labeling the images to be further generated.
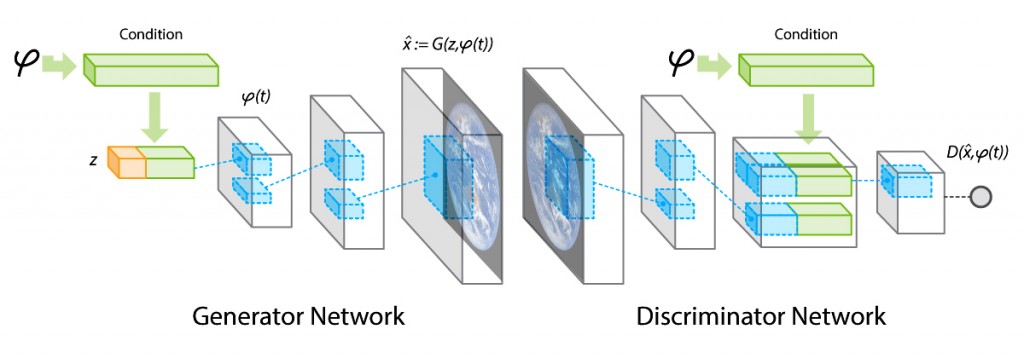
Machine learning for accurate image-to-image translation
During the project’s scope our team faced the following challenges:
- The complexity of the selected algorithm
- The configuration of knobs
- The aggregation and preparation of datasets
- Long iterations
The team successfully continued the research and investigation by aggregating and preparing huge datasets. For the better understanding and editing of random outdoor scenes, we chose the Transient Attribute Dataset. But because of the perceptible lack of data, to achieve better outputs, we decided to utilize additional datasets. The details and samples of those can be found below.
The datasets
Dataset №1. Annotated photos from over 100 webcams with various outdoor scenes.
Our team:
- Downloaded photographs annotated during crowdsourcing campaign
- Picked and filtered photos that has the most vivid characteristics of the winter and summer seasons
- Clustered the selected photos as pairs
That made 3000 pairs of both winter and summer landscapes, 640×480, scaled to 256×256.
 |
 |
Dataset №2. Four 10-hour high-definition videos recorded from the train during the Nordland Line Norway trip in all four seasons.
Our team:
- Downloaded the mentioned videos
- Cut all four videos into frames using FFmpeg
- Auto-aligned the best frames using Python and Hugin
This made 9000 pairs of both winter and summer landscapes, 1000×1000, scaled to 256×256.
 |  |
 |  |
The results
Harnessing knowledge and experience in leveraging computation technology, in particular machine learning, our engineers successfully delivered a solution performing accurate image-to-image translation as an innovative analogy to automatic language translation.
The results can be found below.
| Input | Output | Ground truth |
 |  |  |
 |  |  |
 |  |  |
 |  |  |
 |  |  |
Training set: 11.500 image pairs, testing set: ~600 image pairs. Here are the best setup details:
The best setup details:
- 286×286, scaled to 256×256
- Horizontal mirroring
- Conditional D model
- PatchGAN
The variations
We would also like to share some samples of variations that happened during the training process.
The most typical variations:
- Dataset manipulations and mixing
- Image jitter, random mirroring, the number of epochs
- Unconditional/conditional D models
- PatchGAN/PixelGAN/ImageGAN
| Input | Without jitter: Same detailed patterns everywhere | With jitter. 900×900, scaled to 256×256: Blurred output |
 |   |   |
 |   |   |
| Input | Overloaded dataset №1: Mixed illumination and artifacts | Overloaded №2: No clarity |
| |   |   |
| |   |   |
| Input | ImageGAN: Slightly distorted | PixelGan: Very blurry | L1 regularization: Loss of low-level features |
|  |  |  |
|  |  |  |
Technical details
Used hardware:
- AWS p2.xlarge (NVIDIA GK210 12 GB GPU), CUDA Toolkit
Tech stack:
- Python
- NumPy
- Pandas dataframe
- Hugin tool
- Pix2Pix service
- OpenCV library
How we can benefit your business
Abto Software handles complexities related to computer vision to help mature businesses focus more on data. By harnessing great knowledge and experience in implementing artificial intelligence and its various subsets (machine and deep learning, ANN, NLP), our engineers deliver custom cutting-edge solutions.
We provide:
- Image enhancement and restoration
- Image filtering, deconvolution, transformation and alignment
- Image segmentation and clustering
- Image analysis and key feature detection
And design:
- Driver assistance solutions
- Environment reconstruction tools
- Visitor detection systems
- Body measurement applications
And more on-demand software.
Contact us to design innovative products and win the competition!