AI & NLP solution for assisted agri-biotech research
We built an assistant that turns scattered reports, siloed notes, and messy PDF files into instant, clear insights. The teams can explore the formulations, metabolites, microbes, and diverse plant effects in minutes, not days.
This decreased literature review by 50–60% and increased viable hypotheses by 2-3x.
Services:
Project overview
Our client is an agri-biotech company that turns organic waste into high-performing, sustainable biostimulants. Their internal R&D team was drowning in reports, siloed notes, and messy PDF files, which slowed the research and stretched experimental timelines.
That’s where Abto Software took over.
Our solution: a tailored AI assistant that turns scattered papers into searchable, easily available R&D insights. The platform is designed to digest the diverse internal reports and extract structured metadata to put it behind a fast-working knowledge base.
We turned the search through folders into clean, filtered entities that researchers can pull in minutes, not days.
Main goals
- Accelerate discovery and testing by providing rapid access to insights without digging through files
- Streamline overall R&D throughput
- Empower institutional knowledge reuse by centralizing scattered assets
- Support thought-out resource allocation by eliminating manual routines
The problem
The client was facing multiple problems:
- Historical research was scattered across spreadsheets, slide decks, and numerous PDF documents, thereby making work hard to find and reuse
- Literature reviews on metabolites, abiotic stress, and microbes were sluggish, taking days per question and limiting the number of ideas that could be tested
- End-to-end relationships were buried inside messy ad-hoc spreadsheets
- Answering questions required repeated, error-prone searching
The solution
We delivered a specialized AI assistant to search and surface fitting insights, which includes:
- A tailored AI & ML platform that provides a searchable knowledge base for research
- A trained NLP pipeline
- A secure metadata storage with a RAG-powered assistant
- And lightweight web application for seamless R&D workflows
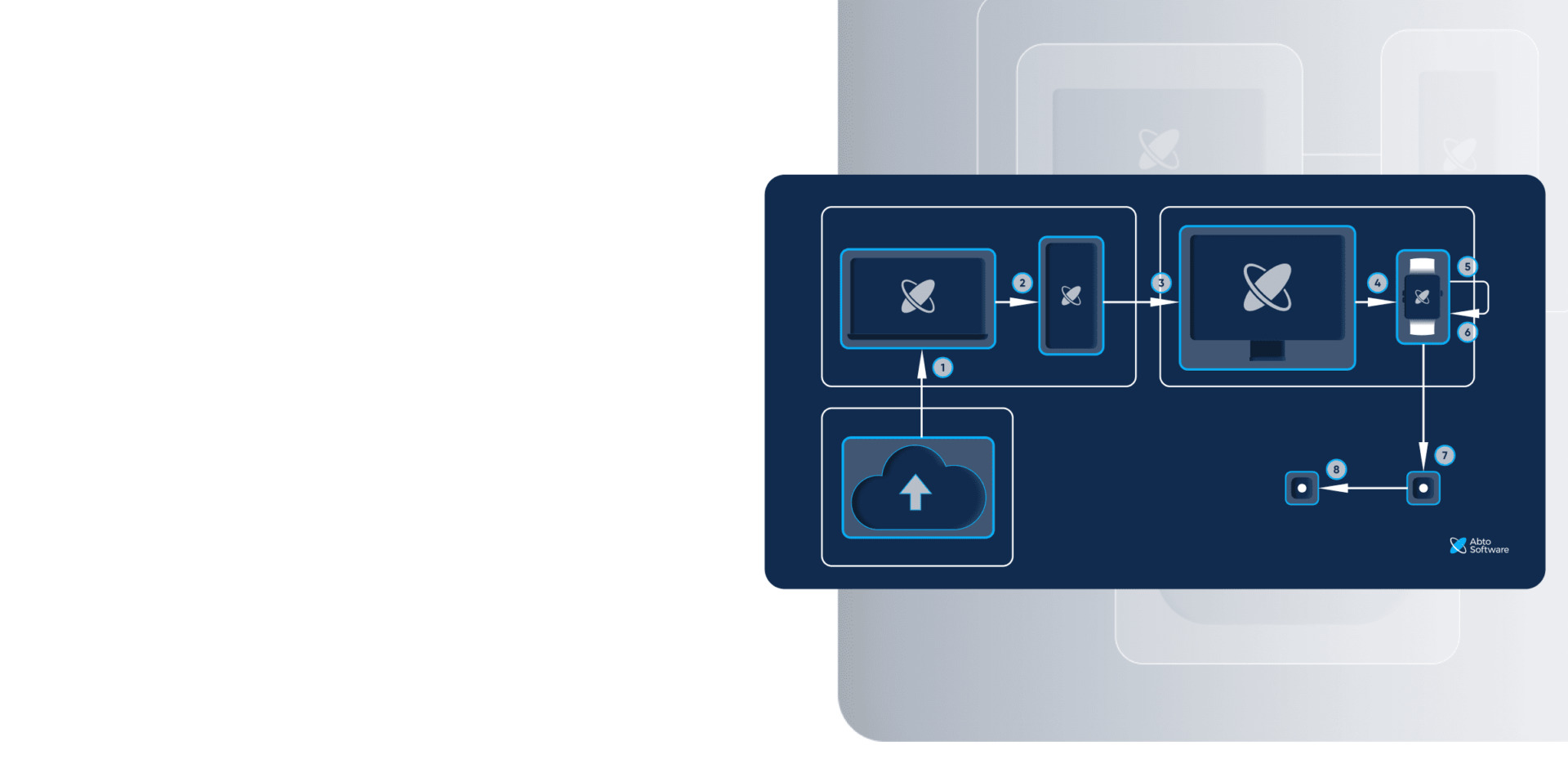
How the solution works
Key features
- All automatic document ingestion and parsing
- NLP pipeline that identifies and structures the research
- A central metadata storage that enables semantic search
- Intuitive interface, which includes:
– A quickly browsable catalog of materials, extraction methods, plant effects, and formulations)
– Various filters by crop, stress type, and other key parameters
– And a chat-style assistant that returns grounded citations
The results:
- The previously scattered reports are centralized into a single corpus that provides consistent metadata
- Key concepts are turned into first-class domain entities that can be filtered and compared
- The time to answer complex questions is reduced from days to minutes
- The groundwork is laid for future functionality extension without re-architecting
Our contribution
- POC delivery
- MVP development
- AI & ML development
- NLP development
- RAG design
- Web development
- UI design
- CI/CD setup
Tools & technology stack:
Backend
- Python
- FastAPI
- AWS Fargate
- AWS Lambda
- Amazon Bedrock
- Amazon SageMaker
Frontend
- React
- Amazon CloudFront
- AWS Amplify
Infrastructure & DevOps tools
- IAM
- CloudWatch
- AWS CodePipeline
- AWS CodeBuild
Data storage
- Amazon S3
- Amazon Aurora PostgreSQL
- Amazon OpenSearch Service
Timeline:
- POC development – 2 months
- MVP development – 5 months
Team:
- 1 project manager
- 1 AI/ML engineer
- 1 backend engineer
- 1 full-stack engineer
- 1 DevOps specialist
- 1 QA specialist
Value delivered to business
We brought the client’s agri-biopharma workflows a big step closer to what pharmacological research relies on. At the same time, this digitalization and automation remains tailored to their domain-specific needs.
Our solution is designed to deliver:
- Stronger decision-making: AI responses are supported by citations from sources and context, empowering researches with confidence
- More reliable, faster tracking: the slow, manual processing of materials is now greatly optimized, allowing researchers to trace end-to-end relationships in minutes, not days
What’s more, a reusable RAG foundation is now in place for optimization and predictive modeling integration. And that without rewriting the platform.
The solution has shown strong results:
- The time to compile literature reviews for new ingredient concepts was reduced by 50–60%
- The number of viable formulation hypotheses per quarter grew 2-3x, a rise from about 3-4 to 8-10 shortlisted concepts
FAQ
How AI help research assistants?
AI agents help research assistants primarily by automating cognitive overload. They instantly read and structure massive volumes of research literature and data into a queryable database, drastically cutting down the time spent on manual review and data entry. This allows research assistants to focus entirely on critical thinking, hypothesis generation, and analysis instead of administrative and repetitive information retrieval.
What types of documents AI can process?
AI can work with all major research document types, including:
- Scientific literature: papers, patents, and review articles (PDFs, HTML).
- Regulatory & clinical: trial protocols, CSRs, and EHR data.
- Internal data: lab reports, experimental outputs (Excel/CSV), and internal technical documents.
- General files: PDFs, Word documents (.docx), Excel spreadsheets, images (scanned documents via OCR), plain text, and web pages (HTML).
Their capability lies in converting this diverse, multi-format input into structured, queryable data.
What if documents are poorly scanned or have wrong formatting?
Poorly scanned or formatted documents significantly reduce AI accuracy because:
- OCR fails: poor quality input reduces OCR performance, yielding garbled text.
- Low confidence: the AI extracts incorrect or incomplete data from the faulty text and flags it as low-confidence
- Human correction needed: this forces research assistants to perform more manual verification and correction.
What is the role of RAG in the research process supported by AI?
RAG (Retrieval-Augmented Generation) is the mechanism that converts a potentially unreliable general-purpose LLM into a trusted, domain-specific AI agent that is safe and effective for handling sensitive research data. RAG:
- Ensures factuality: RAG retrieves evidence from specific, trusted documents (internal reports, papers) before the LLM generates output, drastically minimizing hallucinations.
- Enables private data use: it allows the agent to safely use non-public, proprietary data within a secure environment.
- Provides verification: it ensures the AI can instantly cite the exact source document for every extraction or answer, which is crucial for scientific integrity and audits