
NLP model for sustainability-focused brand research
Project summary
Our custom NLP engine can extract and score brand signals for consumers to find eco-friendly options to buy. The smart NLP model will analyze web content to surface the information (certifications, sourcing, and more) and power the marketplace to support eco choices.
About 64% of consumers say sustainability is among top considerations when purchasing and many are willing to pay a premium for these – on average almost 10%.
Services
Project overview
Our client is a promising US-based sustainability startup. The startup is focused on helping average consumers – mostly the younger generations – in finding relevant information about whether individual brands care about their products being sustainable.
January 2022, the company has approached Abto Software to investigate the opportunity of implementing artificial intelligence to build a marketplace, which would make finding eco-friendly brands significantly easier. Having exhaustive field knowledge and experience in AI and natural language processing, our team took on the project to deliver a product that should be leading on the market today.
Main goals
The project’s main goals:
- Compose a successful PoC to test whether the planned product can be successfully deployed
- Develop NLP (Natural Language Processing) model capable of quickly finding relevant information
Cut through ESG noise


How the solution works
By utilizing machine learning, the solution is able to introduce intelligent navigation. The designed NLP system helps identify document elements, including headers, footers, tables, and charts, and extract relevant details, and extract that information to simplify product discovery.
Also enhanced AI model categorizes and scores found pertinent information via finding specific answers to specific questions (closed and opened).
eCommerce digitalization went from conversational chatbots to business process automation and enhanced customer service. AI and NLP technologies allowed to improve the shopping experience.
Our contribution
The composition of the POC (Proof of Concept) was the initial phase of the solution’s development. The POC was intended to test if the AI based NLP technology can be successfully deployed.
Our team imposed a successful hypothesis and selected a suitable NLP model, considering the project’s goals. After that, our engineers trained the NLP model to collect relevant information from multiple online sources.
The solution encompasses several steps of data processing, which include data harvesting, data scraping, data validation, data evaluation and scoring. Those processes were enabled using various complex tools and apps, requiring full system integration and robustness.
Data validation, data evaluation and scoring were the most edge-cutting processing steps, as the NLP model was designed to differentiate and analyze text arrays. To develop a tailor-made ML model capable of covering the client’s specific requirements, we went through an iterative approach consisting of several stages.
We chose the so-called multi-tier approach consisting of mixed modules to cover use cases with different question types:
- Basic questions containing a specific keyword
- Open questions, which assume exact answers
- Close questions, which assume exact answers
- General questions focused on specific topics
The selected multi-tier approach consisted of:
Approach 1
We started with the Keywords Detector followed by Sentiment Analysis. Keyword detection, which includes string comparison and text similarity distance, together with sentiment analysis captures the relevant content and declines non-affirmative statements.
- In terms of libraries/frameworks we considered Textdistance for string comparison
- Huggingface for sentiment analysis
In this particular case, as an alternative implementation, we can use the Name Entity Recognition model for the keyword recognition. The custom Context Classifier based neural network transformer or a similar machine learning algorithm can be used as a replacement for the Sentiment Analysis.
Approach 2
We continued with Extractive Question Answering, a more complex model that combines extraction and context understanding. This model is based on the so-called BERT- type neural network and trained by Google. It is open source and has multiple APIs and implementations.
Approach 3
We moved to Generative Question Answering, a model based on the most advanced NLP model named GPT-3 (Generative Pre-trained Transformer 3). This model is drawing more information from questions than answers to achieve high performance in both language comprehension and reasoning. This approach provides for better robustness to biased training data and adversarial testing data than state-of-the-art discriminative models.
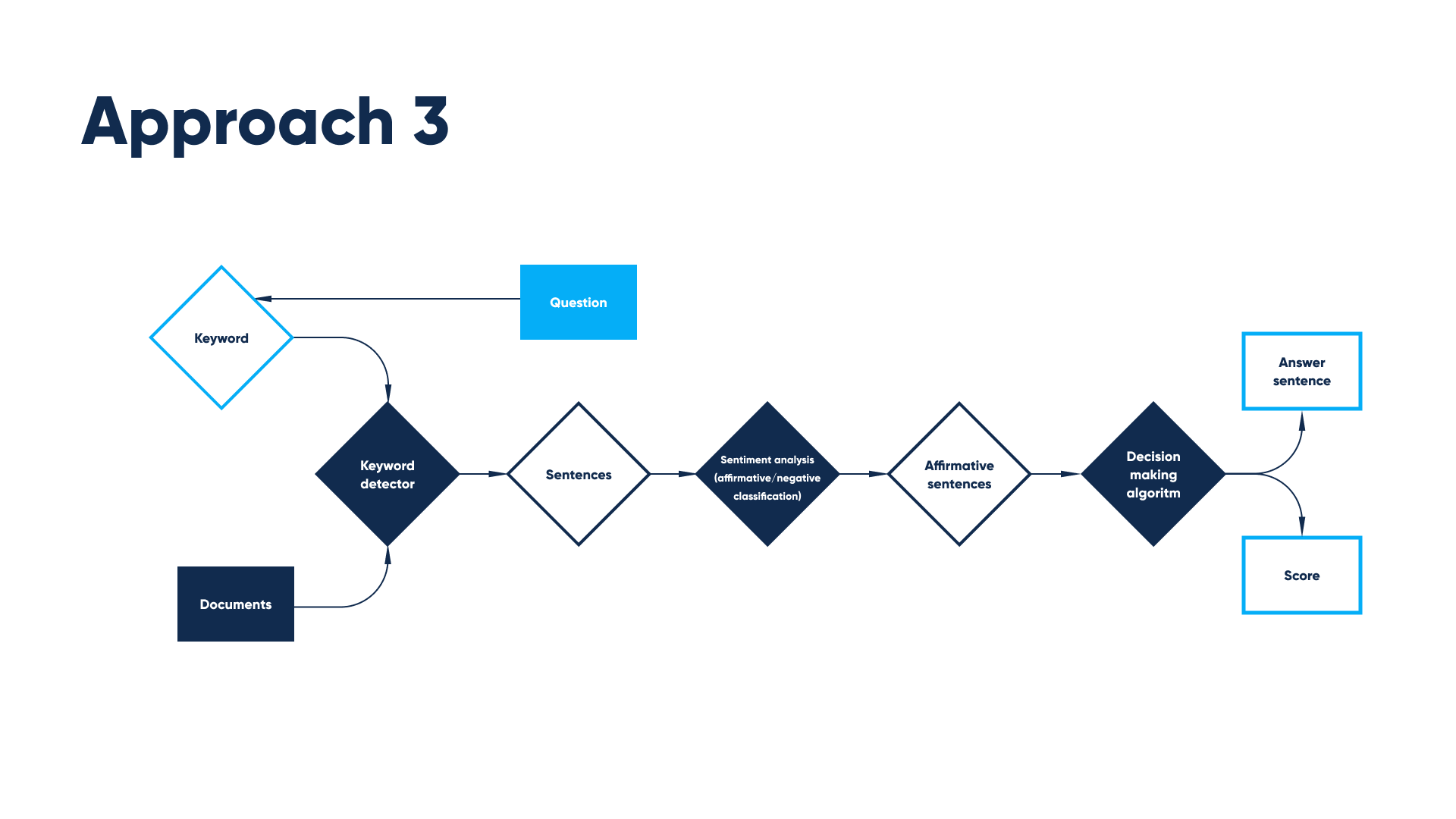
In the first approach, the keyword detector receives web pages documents from the search and keywords deduced from the question. It outputs a set of sentences that may contain relevant information, and then a BERT-like neural network for sentiment analysis analyzes every sentence whether it’s affirmative or negative. And from the number of affirmative sentences is decided whether there is an answer to the question among top web search results, and the answer is chosen.
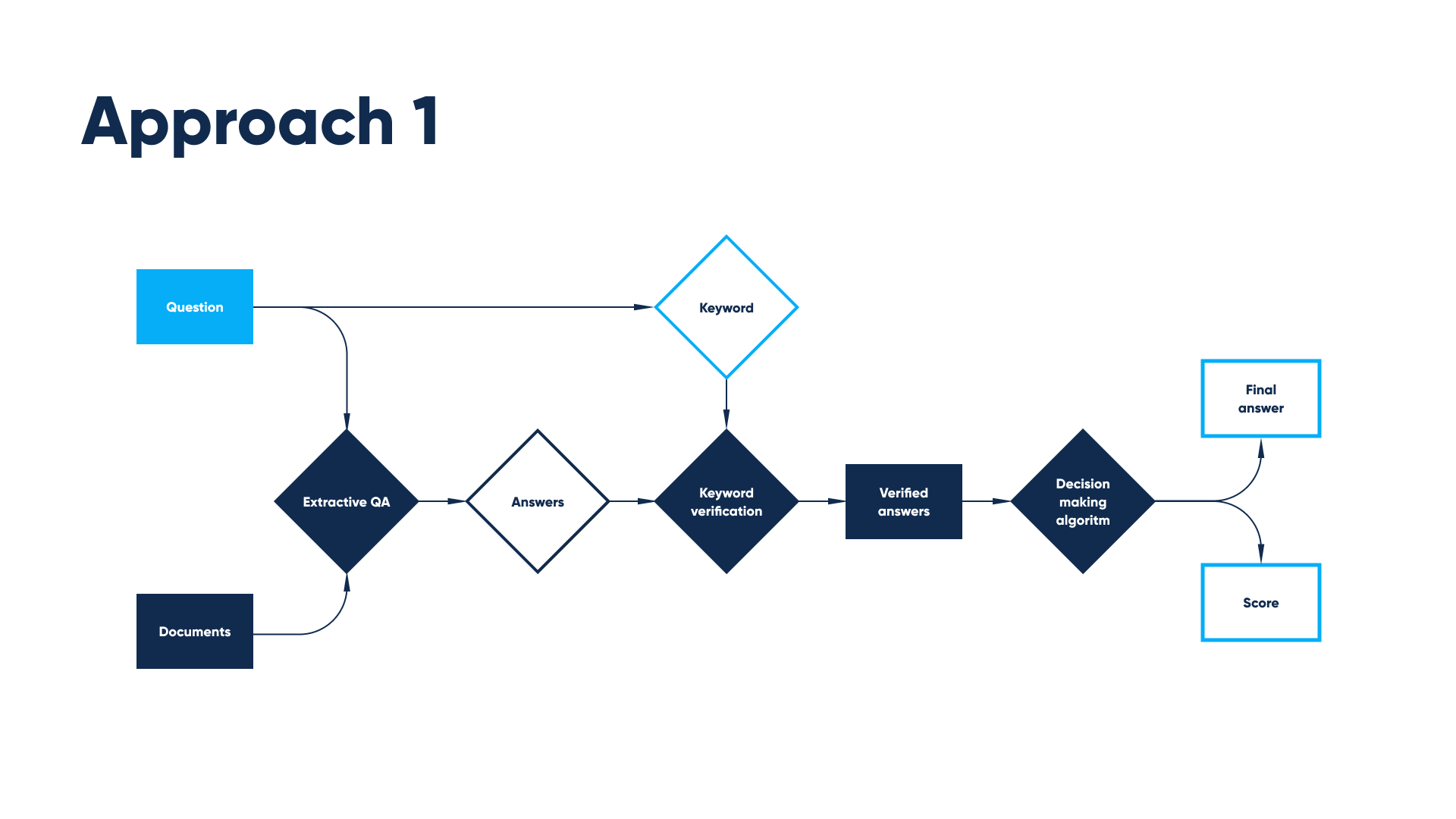
In the second approach, the BERT-like model for extractive question answering takes documents and question as input and outputs an answer for every document. Then a set of answers is filtered through a keyword verification algorithm. In the end the number of verified answers score is calculated and the best answer is chosen.
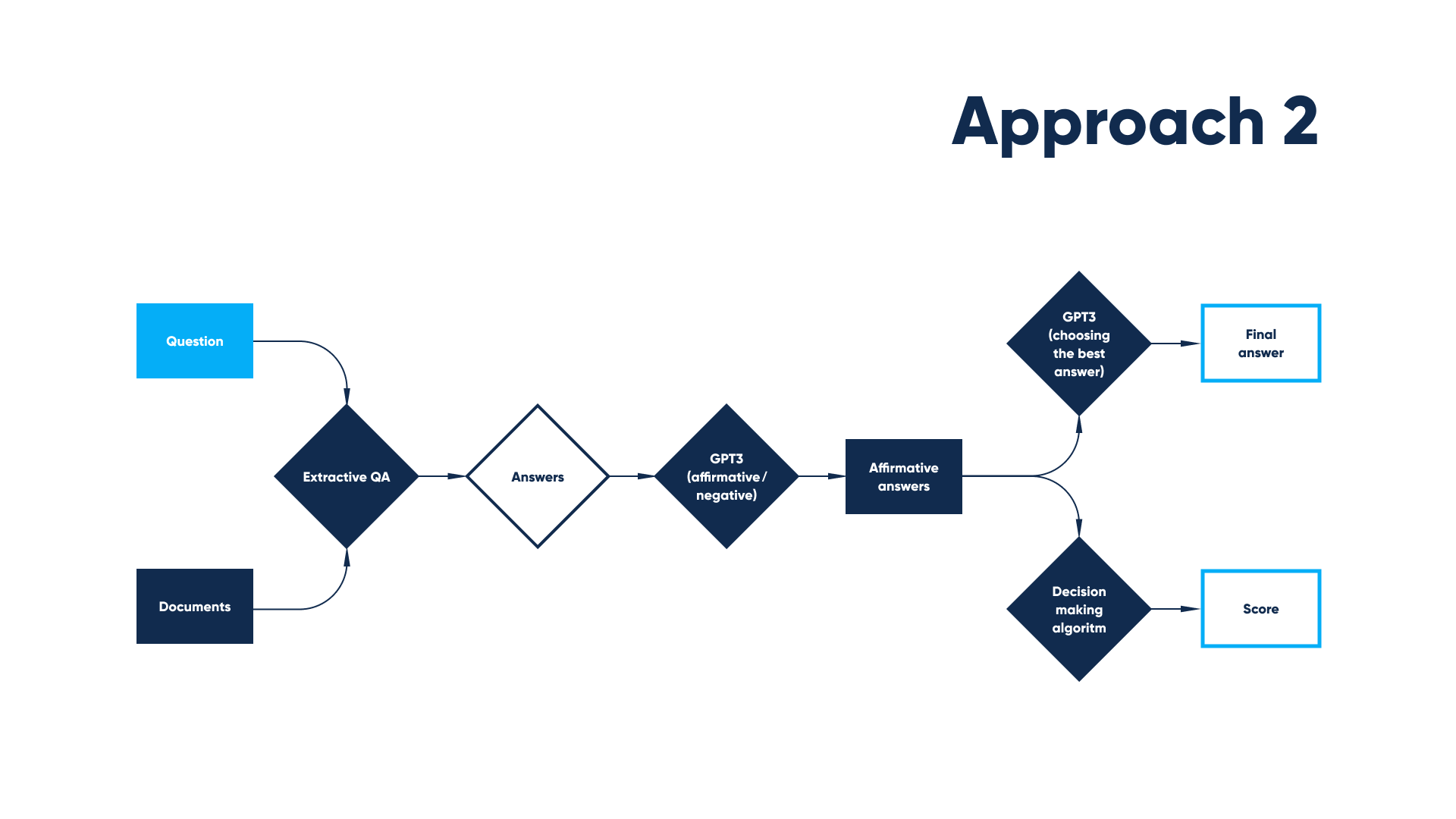
Flow in the third approach also starts from extractive QA, after the answer for every document is received it’s analyzed by GPT3 on whether it’s affirmative or negative. And then from all affirmative answers score is calculated, and GPT3 chooses which one answers the question precisely.
While training the chosen AI based NLP model, our engineers:
- Automated the research process
- Cleared the collected documents/links from metadata
- Built scrapers for the HTML and PDF files to extract relevant information in text
- Transformed the extracted information in a way the designed model could easily process it
During the next steps we covered:
- Primary research process validation. At this stage, we used questions related to one brand.
- Secondary research process validation. At this stage, we used more complex questions related to multiple brands.
- The extension of the NLP model.
- The development of an one-of-a-kind marketplace. At this project stage, we integrated the platform with the NLP technology.
Main challenges
Working on this project, our team faced the following challenges:
- Simplifying requests for the NLP model to process
At the initial stages of the implementation process, when the NLP model isn’t able to extract the information from documents collected on the Internet, the requests made have to be simply formulated.
- Obtaining complete, relevant information
Obtaining information about brands, their production, materials used, labor forces, and other significant details, might be quite challenging because of various reasons:
1. There are only a few brands consciously publishing trustworthy information about production, materials used, labor forces, and other manufacturing details. And so, getting answers to some important questions turns out to be very overwhelming.
2. The availability of information oftentimes depends on the structural organization within companies. Consider, for example, conglomerates. The information about individual affiliated companies, which is generally published by the parent corporation, is usually very generalized. That’s why obtaining details about the brand’s production in detail becomes a tough task.
3. There are some companies that do not own their production. Outsourcing fabrication is gaining momentum today. Many companies delegate production to locations such as India, China, and Turkey. That means, obtaining information about production gets challenging and sometimes even impossible.
4. Some brands conceal information. Some brands, irresponsibly approaching environmental issues, conceal information to avoid potential consequences.
- Selecting the most suitable AI model
Specifically, in our case, a suitable NLP model had to be capable of handling different variants of the same information, since it is ambiguous in nature.
Data-backed insights for actionable green research
Tools and technologies
Programming language:
- Python
AI model technology stack:
- Docker
- TensorFlow
- NLTK
- BERT
- Word embedding
- Deep learning
Timeline:
- January 2022 – June 2022
Team:
- 1 Project Manager
- 1 Solution Architect
- 1 Back-end Developer
- 1 Front-end Developer
- 1 DevOps Engineer
- 1 QA engineer
- 1 Data Analyst
- 1 Data Scientist
Value delivered to business
The developed NLP model provides the following benefits:
- Compliance with global trends, and, accordingly, attraction of potential users
In connection with the increasing popularization of sustainability as a global movement, a project aimed at working towards a more eco-friendly future is without doubt relevant and promising.
- Introduction of a unique search mechanism
The selected NLP model is trained to gather relevant information and display personalized results to match customer intent. This means, users obtain the opportunity to find relevant information, collected in one place, and shop eco-friendly products.