

DevOps for FinTech: Build Secure & Scalable Microservices Architecture with Kubernetes, AWS – Part 2

This is Part 2 from the series of posts dedicated to Abto’s DevOps experience with building secure, reliable and scalable microservices-based architecture for the FinTech.
You can read Part 1 here: DevOps for FinTech using Microservices, Kubernetes, AWS – Part 1.
Introduction
The idea of the project was to build an Artificial Intelligence-based customer service automation solution for the client that works in the fintech domain. The project processes a big amount of sensitive data, which is why the security aspect was very important during project development and further support. The main goal is to process data from a few third-parties and store it to the other remote service. It adds additional difficulties to the task of building a secure and reliable communication between all the involved sides.
In Part 1 we discussed the following topics:
- Project requirements overview
- High-level work overview
- Secure communication
- Logging
Here, we’ll have a look at a more practical side of building the scalable architecture, and present our final thoughts and recommendations.
Application configuration
With a microservice-based approach, managing application configuration is always a challenge. Each of the microservice requires a set of parameters to run, like database connection strings, external api credentials or app-specific logical values. Some of these parameters are environment-specific, some are not. Some of them would be common for all microservice (i.e. logging level), some will be specific to a certain microservice.
With every microservice running in a container and being written in different languages, there is only one good common approach to distribute configuration parameters – via environment variables. For a centralized storage of those parameters we decided to use AWS Secrets Manager, where the parameters are stored in JSON format, and task our CI/CD tools with attaching those parameters to the container on deployment (this is described in more detail in CI/CD section).
Microservice parameters consist of several layers, each one overriding the previous ones:
- Local configuration file, stored in the source code. It usually contains the default values for the parameters.
- “Common” configuration in AWS Secrets Manager – a set of parameters that are applied to all microservices, usually containing some common environment-specific configurations.
- Finally, microservice-specific configuration AWS Secrets Manager, overriding the previous two.
Environment-related Deployment Tools
Lots of things are integrated or pre-installed on AWS EKS but some tools have to be installed on the Kubernetes cluster to provide additional automation features like cluster autoscaling or DNS binding. All of them work based on Kubernetes’ objects modifications, some status/metrics changes, and on objects annotations data.
Additional tools used on the Kubernetes:
- Metrics Server – collects Kubelets resources’ metrics and exposes them in Kubernetes API server through Metrics API for use by Horizontal POD Autoscaler. Metrics API can also be accessed by a kubectl top, making it easier to debug autoscaling pipelines.
- Horizontal POD Autoscaler – automatically scales the number of pods based on provided by Metrics server data like CPU or memory usage. It is a part of the Kubernetes installation and does not require additional modules installation.
- Cluster Autoscaler – is a tool for automated Kubernetes cluster scaling. It is triggered when PODs fail to launch due to lack of resources or when nodes in the cluster are underutilized and their pods can be rescheduled onto other nodes in the cluster.
- ExternalDNS – dynamic DNS binding system with multiple hosting provider support. It retrieves a list of desired DNS records from Kubernetes resources like a Service or Ingress, then configures all the domains in AWS Route 53 DNS zones.
- AWS ALB Ingress Controller – AWS integration tool that triggers an Application Load Balancer and the necessary supporting AWS resources creation whenever an Ingress resource is created on the Kubernetes cluster.
- HELM – package manager for Kubernetes. HELM’s packages are called charts. HELM provides an ability to install lots of charts from public or private repositories. What is more important is that it provides an ability to easily create our charts.
HELM chart
HELM chart gathers all the Kubernetes objects into a single package. All the objects are described as special templates that are used to generate deployment configuration. All the configuration values are stored in the chart’s config file called Values. During the deployment process, the HELM engine renders Kubernetes objects based on templates and supplements them by configs from the values file.
The base HELM chart’ templates used for the standard microservices’ chart. All of them were modified for our needs, as a result, we received a useful basis for all microservices’ charts. The Kubernetes objects described in our chart:
- Deployment – describes, as can be seen from the name, all the workload’s deployment configuration – POD resources described here, additionally, we added health checks and configuration mounting.
- ConfigMap and Secret – special Kubernetes objects for configurations storage. We generate them dynamically from the Values.yaml config file, where a special config block is prepared. All the options are separated into ConfigMap or Secret based on the sensitivity of each parameter because the Secret config storage object has better security. Both objects are generated and attached to PODs on HELM chart deployment or upgrade.
- Service – is an abstract pointer to the PODs group inside the cluster. Provides a unique persistent inside-cluster name for each deployment. We configured it and bound to our Deployment object in the service’s configuration.
- Ingress – controls Kubernetes cluster incoming HTTP/HTTPS traffic (in modern versions it also handles TCP and UDP traffic). It requires a separately deployed Ingress Controller. We selected the AWS ALB Ingress Controller to have an ability to deploy AWS Application Load Balancer by the Ingress object creation.
- HPA – Horizontal Pod Autoscaler – scales the number of PODs based on resource utilization or custom metrics. We configured in here minimum and maximum PODs amount as well as scaling thresholds.
As a result, we have a single HELM chart that deploys all the microservice related things, even AWS services’ instances outside the Kubernetes cluster. Our vision is one HELM chart for one microservice. We follow this approach for all microservices. It simplifies and unifies work with any technology and any amount of microservices.
CI/CD
As we described earlier, we started development with four environments:
- DEV – the latest changes are deployed here, used for quick testing and some mixing with the local development environments.
- TEST – for testing purposes. All the release candidates are deployed here.
- UAT – User Acceptance Testing – for verifying that the solution meets all the end user’s expectations and works according to specifications. Tested by the QA team sources are deployed here.
- PROD – production system for real users access. Fully tested production-ready sources are deployed here.
We selected GIT as a version control system. Each separate microservice has its repository. It provides us with the ability to organize all the microservices in our unified approach – in a single repository we have all the required things to work with and deploy the microservice.
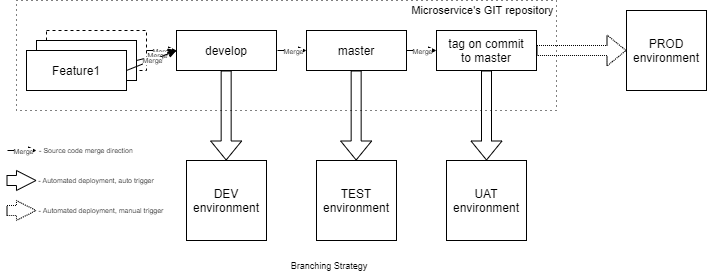
According to the approved simple continuous delivery branching strategy, the source code flow is next:
- each feature is developed in a separate per feature branch. This branch is created on the develop and is merged back when the work on the feature is done; develop branch contains all the latest sources. This latest microservices’ version from the branch is deployed automatically to the DEV environment on each merge request. It provides the ability to run the tests and quickly check the microservice collaboration with the others;
- master branch contains the potential release candidate. It is automatically deployed to the TEST environment to test the solution maximum in detail. QA team mostly works with this environment. Deploy also triggered by GIT merge request;
- each fully tested version of the sources receives a tag with the microservice’s version. Since that moment the version can be deployed to the UAT environment for final pre-release testing. Deployment to UAT is triggering manually as well as selecting a version to deploy;
- at any moment of time, any of the fully tested and tagged microservice’ version can be deployed to the PROD environment. It should be selected and triggered manually by the release manager.
As soon as the development process becomes on flights, continuous delivery will be replaced with continuous deployment. In other words, we will switch to automatic deploy to all including PROD environments to speed up the development.
We follow the strategy for all the microservices development.
Automated deployment was mentioned a few times in the branching strategy but what is it? It is a complex of actions performed by the CI/CD system to ensure that the microservice’s source code will be prepared to be ready for usage and delivered to the hoster. In our case it consists of:
- The system receives a trigger to start deployment (manual or automatic).
- Downloads the latest sources.
- Receives environment-related and the rest configs for the microservice.
- Builds the Docker image. Some tests also can be run on thins stage.
- Uploads the Docker image to the Docker registry.
- Updates (overrides) configs in the Values file of the HELM chart, including microservice version.
- Installs HELM chart (install or upgrade depending on the current microservice state on the destination Kubernetes cluster).
- Kubernetes objects creation/updating process triggers the next activities:
- Kubernetes worker node downloads a new Docker image for Docker instance creation on the Deployment object change.
- AWS ALB Ingress Controller requests AWS ALB deployment (or config update) on Ingress object change.
- ExternalDNS creates or updates AWS Route 53 DNS records on the Ingress object’s annotations creating or updating.
- Runs tests.
- Collects the deployment results and informs the team (if needed).
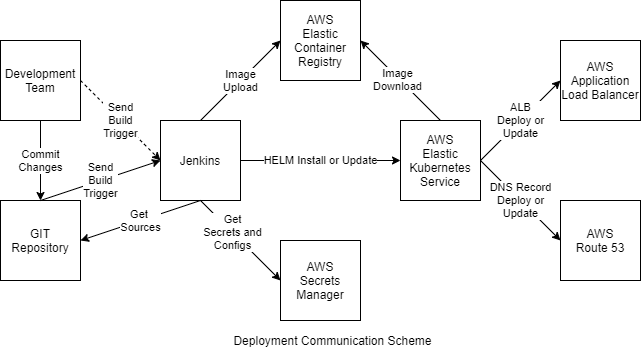
As the system, we selected Jenkins – a widely spread popular open-source automation server with hundreds of plugins.
Each microservice has own multi-branch pipeline deployment rules definition for each environment. The multi-branch pipeline is a special Jenkins object that scans all branches in the repository for Jenkinsfile, Groovy script that describes all the build, test, and deploy steps. As a result, we have two main benefits:
- Jenkinsfile is stored in the microservice’s repository – we follow our strategy – all the related to microservice things are stored in a single place.
- We can deploy any branch to any environment at any time manually. It is along with automatic deployments described in the branching strategy. It is very useful for quick tests, for example, some feature’s branch deployment to the DEV environment for checking collaboration with others without the need to merge it to the develop.
The microservice configurations are modified a few times during deployment and have a linear imitation (every next level supplements/overrides the previous ones):
- Service configs are described in the local config files that are packed into a Docker container with the sources.
- Default options in the HELM Values file, that are attached to the Docker container instance at startup as a local environment variables.
- Options that were added to the HELM chart as arguments on chart installation or update procedure. These options are options collected from AWS Secrets Manager.
Jenkins collects options for each microservice in each environment from AWS Secrets Manager then attaches them to the Docker instance on the HELM chart deployment stage via additional “set” CLI keys that supplement or override described in the Values configurations as described above.
Local development environment
The solution consists of a big amount of microservices. The development team can work with some parts of them or even with all simultaneously. It is important to have some solution for a quick and easy local development environment set up and further maintenance. That is why we developed a special system for local machine configuration and the project’s day-to-day development activities.
The key options of the system:
- based on Docker, Docker-compose, and BASH;
- placed into a single separate GIT repository;
- works on Windows, Linux, and Mac OS;
- one click for microservices local deployment;
- ability to select desired microservices to deploy;
- easy microservices rebuild;
- bulk sources updates;
- ability get configuration from the AWS Secrets Manager;
- services that aren’t deployed locally can be used from the AWS DEV environment trough the IPSec VPN tunnel.
The system permits us to use Docker containers for local development which is maximum close to further production use. It supports easy deployment what is important when new team members start work on the project as well as bulk sources update for the day-to-day work of all the members.
It does not matter what programming language or on what operation system team members work with – the system will help and speed up all the preparations and day-to-day work.
Pros, cons and further improvements
We tried to meet all the requirements and develop the maximum useful system. We ended up with the architecture that provides us with the next benefits:
- modular – each microservice has its repository where stored everything related to the microservice – from the source code till the deployment rules;
- high security – each microservice’s instance packed into a Docker container, everything isolated as much as possible, detailed all systems state monitoring is configured, all the outside VPC connections are encrypted;
- automatic horizontal scaling – each microservice is scaling up independently to handle any load it receives;
- comfortable work with Kubernetes – HELM chart deploys the microservice in one command;
- unified work with any programming language – each microservice is packed into the Docker container, listens standard HTTP port, has standard health metrics – it does not matter on what language it is written, deployment and hosting process will be the same;
- quick new microservices adding: copy microservice repository template, add standard Jenkins deployment rules (just change the name), and start the development process;
- central logging service – Elastic stack provides tools for quick information on any change in the system.
Improvement is a continuous endless process. At the moment of the article preparation, we see a few points of improvement soon:
- try to move the local development environment to local Kubernetes (Docker desktop supports it) to make local and production environments more similar;
- add AWS WEB Application Firewall rules to improve project security by advanced HTTP request filtering;
- continuously improve monitoring by adding additional info for storage, filtering of irrelevant log entries, adding new more informative dashboards, and configure the alert system to inform the support team at all the events that require intrusion;
- review the pros and cons try to merge per-service AWS ALB instances into a single or a few ones to reduce costs.
Conclusions
During the MVP version development, we developed a pretty universal CI/CD and hosting solution for the Kubernetes-hosted microservice architecture project. All the components, environments, and development or data providers’ sides are highly isolated which with the rest of the activities provides maximum security.
The central logging system controls all the working metrics and informs the support team as well as store all the data for manual review and analysis.